
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 에이블데이
- 해외연수
- jupyter notebook
- 자연어처리
- keras
- 코딩테스트
- KT에이블스쿨
- KT AIVLE SCHOOL
- 내일배움카드
- sklearn
- kaggle
- HUFS
- 미니프로젝트
- AIVEL
- AI
- 내배카
- Python
- 에이블스쿨
- YOLO
- 딥러닝
- Aivle school
- 부트캠프
- pandas
- 한국외대
- KT
- numpy
- Anaconda
- AIVLE
- 에이블스쿨6기
- KT wiz
- Today
- Total
Hyunn
컴퓨터네트워크 - 3탄(2장) 본문
2장: 애플리케이션 계층
2.1 네트워크 애플리케이션의 원리
2.1.1 네트워크 애플리케이션 구조
- 클라이언트-서버 구조
- 항상 켜져 있는 호스트: 서버(고정된 IP주소)
- 서버에게 요청하는 호스트: 클라이언트(dynamic IP주소)
- 클라이언트는 서로 직접적인 통신을 하지 않는다.
- P2P구조(Peer-to-peer)
- 서버에 최소한으로 의존한다.
- 피어(peer)라는 간혈적으로 연결된 호스트 쌍이 직접 통신한다.
2.1.2 프로세스간 통신
클라이언트와 서버 프로세스
- 두 프로세스 간의 통신 세션에서 통신을 초기화(다른 프로세스와 세션을 시작하기 위해 접속을 초기화)하는 프로세스를 "클라이언트", 세션을 시작하기 위해 접속을 기다리는 프로세스를 "서버"라고 한다.
ex) 웹에서 브라우저 프로세스는 클라이언트, 웹 서버 프로세스는 서버이다.
프로세스와 컴퓨터 네트워크 사이의 인터페이스
- 프로세스들은 "소캣(socket)"을 통해 네트워크 메시지를 보내고 받는다. (애플리케이션과 네트워크 사이 API라고도 함)
cf) 2.7절에서 더 자시히 다룸
프로세스 주소 배정
- 수신 프로세스를 식별하기 위해 (1) 호스트의 주소 (2) 목적지 호스트 내의 수신 프로세스를 명시하는 식별자가 필요하다.
- (1)은 IP주소로 식별 가능
- (2)는 포트번호로 식별 가능(웹서버: 80, 메일서버: 25 ...)
ex) HTTP메시지를 hufs.ac.kr에 전송 --> IP address: 203.202. xxx.xxx / port num: 80
2.1.3 애플리케이션이 이용 가능한 트랜스포트 서비스
- 트랜스포트 계층이 애플리케이션에게 제공할 수 있는 서비스: 신뢰적 데이터 전송, 처리율, 시간, 보안
1) 신뢰적 데이터 전송(Data integrity)
- 애플리케이션이 보낸 데이터가 올바르고 다른 애플리케이션에 전달되도록 보장한다.
- 보장하지 않는 트랜스포트 서비스를 사용한 애플리케이션: 손실 허용 애플리케이션( ex) 스트리밍 서비스 etc.)
2) 처리량(Througput)
- 어느 명시된 속도에서 보장된 가용 처리율을 제공한다.
- 처리율 요구사항을 갖는 애플리케이션: 대역폭 민감 애플리케이션( <-> 탄력적 애플리케이션 ex) e-mail )
3) 시갼(Timing)
- 송신자가 보내는 데이터가 수신자에게 도착하는 시간 보장
4) 보안(Security)
2.1.4 인터넷 전송 프로토콜이 제공하는 서비스
- TCP: Transmission Control Protocol
- UDP: User Datagram Protocol
1) TCP서비스
- 연결지향형 서비스 제공: 애플리케이션 계층 메시지 전송 전, TCP는 클라이언트와 서버가 서로 전송제어 정보를 교환하도록 함.
- 신뢰적인 데이터 전송 서비스: 모든 데이터를 오류없이 전송을 보장함
- 암호화는 제공하지 않는다.
2) UDP 서비스
- 간단한 전송 프로토콜
- 비신뢰적인 데이터 전송
- TCP에 비해 빠르다.

2.2 웹과 HTTP
2.2.1 HTTP 개요
웹 페이지
- 객체: 예를 들면, HTML파일, 이미지 같은 것들을 의미
- HTML파일은 객체를 그 객체를 갖고 있는 호스트 네임, 객체의 경로를 표현한다.
ex) hufs.ac.kr/picture.gif에서 호스트네임은 hufs.ac.kr, 객체 경로는 /picture.gif이다.
HTTP
- 웹 클라이언트가 웹 서버에게 웹 페이지를 어떻게 요청하는지와 서버가 클라이언트로 어떻게 웹 페이지를 전송하는지 정의
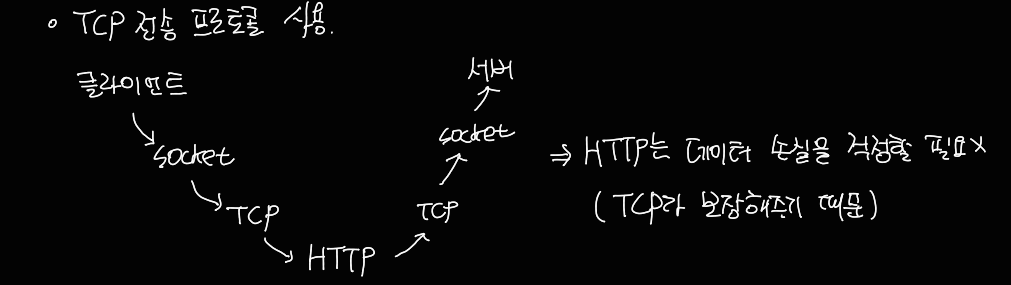
2.2.2 비지속 연결과 지속 연결
비지속 연결 HTTP(HTTP 1.0)
- 연결 수행 과정
- 클라이언트가 TCP연결을 시도한다.
- TCP연결 소캣을 통해 요청 메시지를 서버에게 전송한다.
- 요청 메시지를 받은 서버는 객체를 추출한다. 그리고 캡슐화 작업 후 클라이언트에게 전송한다.
- TCP연결을 종료한다.
- 클라이언트는 HTML파일의 다른 개체에 대한 참조를 찾는다.
- 그 객체에 대해 1~4번 과정을 반복한다.
- RTT(Round-Trip Time): 패킷이 클라이언트 -> 서버 -> 클라이언트로 오는데 걸리는 시간을 의미한다. 즉, 패킷전파지연 + 큐잉지연 + 처리지연이다.
- 첫 객체 통신 RTT: 2RTT + 파일 수신시간
- TCP 요청
- 서버응답 -------------- 1RTT
- 클라이언트 응답 + 서비스 요청
- 응답 --------------------- 2RTT
- 파일 전송 -------------- 파일 수신 시간
지속연결 HTTP(HTTP 1.1)
- 비지속 연결의 단점: 각 객체를 보낼 때마다 새로운 연결이 설정되어야 하므로 각 객체는 2RTT를 필요로 한다.
따라서 HTTP/1.1은 지속 연결은 서버가 응답을 보낸 후에 모든 객체가 전송될 때까지 TCP연결을 유지한다. 즉, 클라이언트-서버의 연결을 위해서는 1RTT만 소요된다.
2.2.3 HTTP 메시지 포맷
특징
- 일반 ASCII텍스트로 쓰여있다.
- 5줄로 되어 있고 각 줄은 CR과 LF로 구별된다.('\n', '\r')
요청메시지(request line)
- 헤더라인
- HTTP 메시지의 아래 4줄
- Host: 객체가 존재하는 호스트 명시
- Connection: 지속연결의 유무
- User-agent: 클라이언트의 브라우저 타입
- Accept-langauge: 사용자가 원하는 언어 종류(프랑스어, 영어, 한국어 ... )
- 개체 몸체
- GET방식에서는 비어있다.
- POST방식에서는 클라이언트가 폼(form)에 입력한 값을 추가한다.
- HEAD방식: GET 방식과 유사 (잘 아는 실력자님 알려주세요...)
- PUT방식: 웹 서버에 업로드 할 객체를 필요로하는 애플리케이션에서 사용
- DELETE방식: 사용자(애플리케이션)가 서버에 있는 객체를 지우는 것을 허용
HTTP 응답메시지
- 상태라인: 프로토콜 버전, 상태코드, 해당 상태 메시지
- 헤더라인: Connection, Data(응답 메시지를 보낸 시간), Server(서버종류 및 버전), Last Modified(객체 마지막 수정 시간), Connect-Length(객체 바이트 수), Connect-Type
- 객체 몸체: 요청한 객체 데이터
| 상태코드 | 의미 |
| 200 | OK(요청 성공) |
| 301 | Move Permanently(현재 링크나 레코드가 업데이트 되어야 함) |
| 400 | Bad Request(잘못된 요청) |
| 404 | Not Found(해당 주소 찾을 수 없음) |
| 505 | HTTP Version Not Supported |
2.2.4 사용자와 서버간의 상호작용: 쿠키
- 쿠키의 필요성: 서버가 사용자 접속을 제한 / 사용자에 따라 다른 콘텐츠를 제공 => 서버가 사용자를 확인할 필요가 있음
- 쿠키의 기능: 사이트가 사용자를 추적함
- 쿠키의 요소
- HTTP응답 메시지 쿠키 헤더라인
- HTTP요청 메시지 쿠키 헤더라인
- 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속하는 쿠키 파일
- 웹사이트 백엔드 DB
=> 서버는 사용자를 쿠키 번호로 인식하고 이를 DB에 저장한다. 사용자의 브라우저는 서버가 제공해주는 쿠키 번호를 로컬에 저장하고 동일한 웹 페이지에 접속할 때마다 요청 메시지와 쿠키번호를 서버에 보낸다.
2.2.5 웹 캐싱(프록시 서버)
- 웹 캐싱이란: 웹 서버를 대신해서 HTTP 요구를 충족시키는 네트워크 개체
- 수행 방식
- 브라우저는 웹 캐시와 TCP연결을 설정 후 HTTP 요청을 보냄
- 웹 캐시는 요청 객체의 사본이 자신에게 있는지 체크한다. 있다면, 클라이언트 브라우저로 HTTP응답 메시지와 함께 전송한다.
- 없다면, 원 출처 서버에 TCP연결을 요청한다. 이후 클라이언트 요청 객체를 요청하면 기점 서버는 웹 서버에 HTTP응답 메시지와 함께 전송한다.
- 웹 캐시가 이를 수신하면 객체의 사본을 저장하고 HTTP응답 메시지와 함께 그 사본을 클라이언트 브라우저에 전송한다.
=> 캐시는 서버이면서 클라이언트 역할을 수행한다.
- 장점
- 응답시간이 감소한다.
- 한 기관에서 인터넷으로 접속하는 링크의 웹 트래픽이 감소하므로 발생하는 비용이 줄어든다.
- 인터넷 전체의 웹 트래픽이 감소한다. 따라서 모든 애플리케이션의 성능이 향상될 수 있다.


- 조건부 GET(Conditional GET): 캐시의 문제는 캐시 내부의 객체가 최신화가 안된 상태일 수 있다는 점이다. 따라서 웹 서버에 브라우저 대신 조건부 GET을 보낸다. If modified- since 헤더를 보내는데, 웹 서버는 날짜를 확인 후 최신화된 것이 없다면 "304 Not Modified"를 보내고 있다면 캐시가 요청하는 객체를 보낸다.
- HTTP/2.0과 3.0
- 2.0은 객체를 frame단위로 쪼개어 보낸다.
- 3.0은 구글이 개발한 것으로 QUIC방식을 사용한다.

2.3 인터넷 전자메일
- 전자메일의 요소
- 사용자 에이전트: 메시지를 읽고, 전달하고, 저장할 수 있게 해준다.
- 메일 서버: 메일박스로 수신된 메일을 유지 및 관리한다.
- SMTP: 전자메일을 위한 애플리케이션 프로토콜이다.
2.3.1 SMTP
- SMTP는 모든 메일의 몸체는 7bit ASCII이어야 한다!
- SMTP의 동작 과정
- 송신자는 전자메일 사용자 에이전트를 수행하고 수신자의 메일 주소를 제공, 메시지 작성 후 사용자 에이전트에게 전송을 명령한다.
- 사용자 에이전트는 이를 송신파 메일서버에 보내고 메시지 큐에 놓는다.
- 송신자 서버의 SMTP는 클라이언트 측에 메시지 큐에 있는 메시지를 본다. 수신자 SMTP서버와 TCP연결을 시도한다.
- 핸드셰이킹 후 SMTP클라이언트는 TCP연결을 통해 메시지를 전송한다.
- 수신자 서버 SMTP는 메시지를 수신한다. 메일 서버는 이를 수신자 메일박스에 놓는다.
- 수신자는 사용자 에이전트를 실행시켜 이를 읽는다.
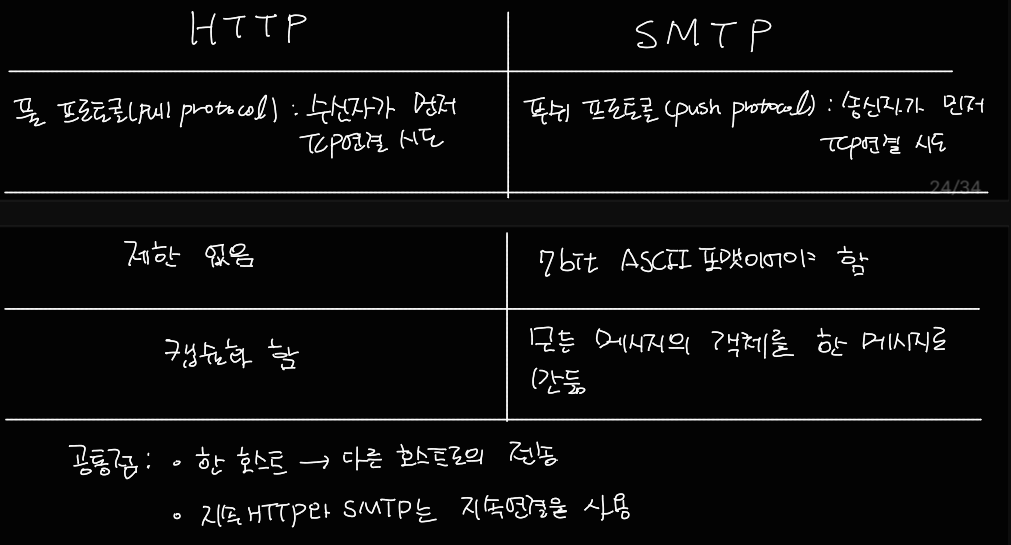
2.3.2 HTTP와 SMTP 비교
2.3.3 메일 메시지 포맷

2.3.4 메일 접속 프로토콜
- POP3(Post Office Protocol Version 3)
- IMAP(Internet Mail Access Protocol)
- HTTP
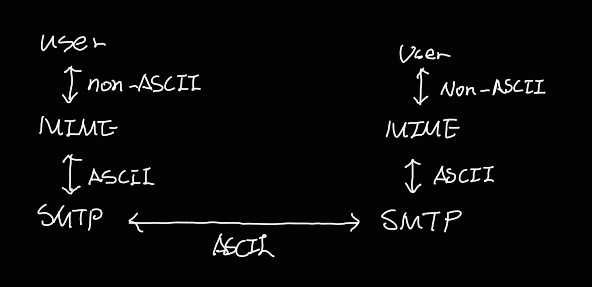
- MIME(Multipurpose Internet Mail Extension): ASCII code로 되어있지 않은 메시지를 SMTP전송을 위해 ASCII code로 바꿔주는 프로토콜
2.4 DNS(Domain Name System) - 인터넷 디렉터리 서비스
2.4.1 DNS가 제공하는 서비스
- 호스트 엘리어싱: 호스트 네임에 별명을 만들어 줌!
- 메일 서버 엘리어싱: 전자메일 주소의 별명도 만들어줌!
- 부하분산: 여러 중복 서버들 사이에서 트래픽을 분산시켜 줌!
2.4.2 DNS 동작 원리 개요
분산 계층 데이터베이스
- 루트(root) DNS 서버: 최상위 레벨 도메인 네임(TLD, Top-Level Domain) DNS 서버
- 책임 DNS 서버
ex) www.amazon.com 의 IP주소 찾기
- 루트 서버에 접속
- 최상위 도메인 .com을 갖는 TLD서버 IP주소를 보낸다.
- TLD서버에 접속
- amazone.com을 가진 책임 서버의 IP주소를 보낸다.
- 책임 서버에 접속
- 서버는 www.amazone.com의 IP주소 전송
- 로컬 DNS 서버: ISP들은 로컬 DNS서버를 갖고 있으며, 대체로 호스트와 가까이 있다.
-재귀적 질의와 반복적 질의


- DNS캐싱: 질의 사슬에서 DNS서버가 DNS응답을 받았을 때, 로컬 메모리에 응답에 대한 정보를 저장한다. 즉, 서버의 IP주소를 얻기 위해서는 항상 루트 DNS서버에 접속할 필요가 없어진다. --> 성능 향상!
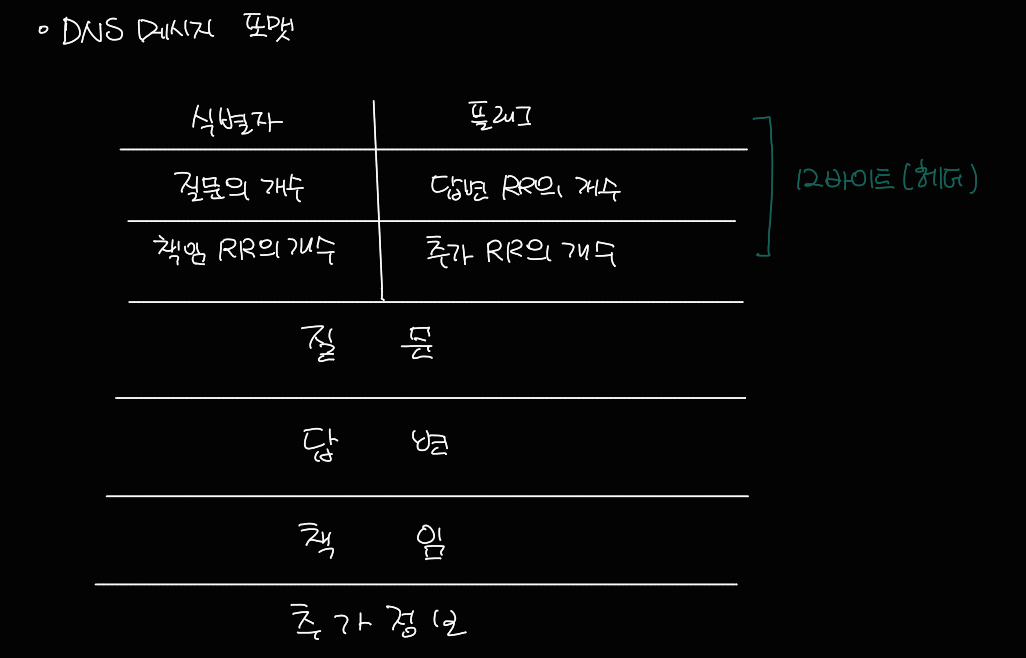
2.4.3 DNS 레코드와 메시지
- DNS분산 데이터베이스를 구현한 DNS 서버들은 호스트 주소를 IP주소로 매핑하기 위한 자원 레코드(resourse record, RR)를 저장한다.
- 자원 레코드 필드(튜플): (Name, Value, Type, TTL)
- Name과 Value의 의미는 Type에 따라 다름
- TTL은 자원이 캐시에서 제거되는 시간을 결정한다.
- Type = A: Name은 호스트네임, Value는 호스트네임의 IP주소
- Type = NS: Name은 도메인, Value는 도메인 내부의 호스트에 대한 IP주소를 얻을 수 있는 방법을 아는 책임 DNS서버의 호스트네임
- Type = CNAME: Name은 별칭 호스트 네임, Value는 정식 호스트 네임
- Type = MX: Name은 메일 서버의 별칭 호스트 네임, Value는 정식 호스트 네임
ex) (foo.com, mail.bar.foo.com, MX)
-> 책임 DNS서버는 Type A 레코드를 포함하고 TLD DNS서버는 Type NS 레코드를 포함한다(반드시 그렇지는 않다고 한다).
DNS Security
- Sniffing을 통해 클라이언트가 요청하는 DNS에 대해 Spoofing DNS reply를 할 수도 있다. => DNSSEC
- New RRS
- RRSIG: 암호화된 RR
- DNSKEY: Public Key(ZSK, KSK)
- DS: KSK의 Hash값
- ZSK: Zone Sign Key(Zone에 속한 RR set을 암호화)
- KSK: Key를 함호화하는 Key(Key sign Key)
- 동작원리
- public KSK는 상위 zone에서 보증해줌
- 암호화: private ZSK로 RRset을 암호화하고 이를 KSK로 암호화한다.
- 복호화
- 상위 DNS서버로부터 인증받은 현재 DNS서버의 KSK인 DS값은 DNSKEY를 unlock하고 public ZSK를 얻는데 사용한다.
- public ZSK는 RRSIG DS & RRSIG RRset을 unlock하는데 사용한다.
- 즉, public ZSK가 없으면 ZSK도 얻을 수 없음
- Root DNS Server: 아날로그 문서로 인증한 DS는 root KSK이다. 이는 root DNSKEY 복호화와 root의 public ZSK를 얻기위해 사용된다. root의 public ZSK는 RRSIG DS와 RRSIG RRset을 풀기위해 사용된다.
- TLD DNS Server: root로부터 인증받은 DS는 TLD KSK이다. 이는 TLD DNSKEY 복호화와 TLD Public ZSK를 얻기위해 사용된다. TLD Public ZSK는 RRSIG DS와 RRSIG RRSet을 풀기위해서 사용된다.
- 책임 DNS Server: (위와 동일 함)
- Local DNS Server: (위와 동일 함)
2.5 P2P 파일 분배
- P2P구조는 서버에 최소한으로 의존한다. 대신, 간혈적으로 연결되는 호스트(피어)들이 서로 직접적으로 통신한다.
- P2P구조의 확장성
- 서버의 접속 링크 업로드 속도: Ui
- i번째 피어의 접속 링크 다운로드 속도: Di
- 분배되는 파일의 크기: F
- 파일의 복사본을 얻고자 하는 피어의 수: N
- 분배시간: 모든 N개의 피어가 파일을 얻는 데 걸리는 시간
1) 클라이언트 - 서버 구조: 분배시간(Dcs)
- 이 구조에서는 어떤 피어도 파일 분배에 도움을 주지 않는다.
- 서버는 파일 F를 N개의 피어에게 Di속도로 전송한다. => NF / Us
- Dmin이 가장 낮은 다운로드 속도를 가진 피어이다. => Dmin = Min(d1, d2, d3.... dn)
Dmin의 다운로드를 가진 피어는 N/Dmin시간이 걸린다.

2) P2P구조 분배시간(Dp2p)
- 각 피어들은 파일 분배에 도움을 준다.
- 서버는 적어도 한 번은 파일 전송이 있어야 한다. => F/Us
- 가장 낮은 다운로드 속도를 가진 피어 => Dmin = F / Dmin
- 시스템의 전체 업로드 용량: 서버의 업로드 속도 + 각 피어들의 업로드 속도
=> Utotal = Us + U1 + U2 + .... + Un
시스템은 N개의 피어들에게 F만큼 전달하여야 한다. 이는 Utotal보다 빠를 수 없다.

3) 클라이언트-서버 vs P2P

틀린 내용, 부족한 내용, 이해가 안가는 내용이 있다면 언제든 댓글로 알려주세요 환영합니다.