
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- KT AIVLE SCHOOL
- 미니프로젝트
- YOLO
- sklearn
- AIVEL
- 코딩테스트
- 자연어처리
- numpy
- HUFS
- AIVLE
- 부트캠프
- KT
- 에이블스쿨
- 에이블데이
- 에이블스쿨6기
- 한국외대
- 내배카
- KT wiz
- kaggle
- Python
- Anaconda
- AI
- keras
- 내일배움카드
- 해외연수
- KT에이블스쿨
- 딥러닝
- jupyter notebook
- Aivle school
- pandas
- Today
- Total
Hyunn
[KT AIVLE School] AI트랙 2주차 후기(데이터 처리, 데이터분석 및 의미찾기) 본문
2주차 일정
02.26 ~ 27: 데이터 처리
02.28 ~ 29: 데이터 분석 및 의미찾기
03.01: 삼일절 휴강
02.26 - 데이터 처리(1)
이 날도 1주차와 마찬가지로 Pandas로 데이터를 처리하는 방법에 대해 배웠고 시계열데이터를 다뤘다. 그리고 데이터 분석 방법론(CRISP-DM)에 대해 배웠다.
데이터프레임 변경
열 이름 변경하기
# 첫 번째 방법 -> 모든 column의 이름을 변경
tip.columns = ['a', 'b' , ... ,'f']
# 두 번째 방법
tip.rename(columns={'a' : 'g',
'b' : 'h',
...
}, inplace=True)
# key : value로 값을 변경할 수 있다.
# inplace=True를 하면 실제 데이터프레임의 값이 변경된다.열 추가, 삭제, 변경하기
# 열 추가하기 -> 없는 열 이름을 지정하고(total) 어떤 값이 들어가는지 설정한다.
## total이라는 열을 만들고 a열에 있는 값과 b열에 있는 값을 더해서 값을 채운다.
tip['total'] = tip['a'] + tip['b']
# 열 삭제하기 -> drop()메소드를 사용한다.
## 열 삭제는 매우 신중히 진행해야 한다. 따라서 보통은 데이터프레임 복사본을 만들고 진행한다.
tip.drop('total', axis=1, inplace=True) # total열 삭제(열을 삭제하기 위해서는 axis가 1이어야함)
tip.drop(['total', 'a'], axis=1, inplace=False) # 여러 열을 한 번에 제거할 수도 있다.
# 값 변경하기
tip['tip'] = 0 # tip열의 모든 값을 0으로 변경
# 조건에 의한 변경1
tip.loc[tip['total'] < 10, 'is_satisfy'] = 'bad' # tip데이터프레임의 total열의 값이 10보다 작은경우 is_satisfy값을 'bad'로 변경
# 조건에 의한 변경2
tip['is_satisfy'] = np.where(tip['total'] < 10, 'bad', 'good')map, cut
- map: 기존 값을 다른 값으로 변경(매핑)
- cut: 숫자형을 범주형 변수로 변환
ex) 나이 -> 나이대 / 고객 구매액 -> 고객 등급
# map 사용하기
## Male은 1로, Female은 2로 매핑
tip['sex'] = tip['sex'].map({'Male' : 1, 'Female' : 0})
# cut 사용하기
## tip_grp이란 열을 만들고 tip열을 3등분해서 이름을 정한다.
tip['tip_grp'] = pd.cut(tip['tip'], 3, label=['Diamond', 'Gold', 'Silver'])
### 그러나, 사용자가 범위를 지정하는 것이 일반적이다.
age_grp = pd.cut(data['Age'], bins=[0, 20, 40, 60, 80, np.inf], label=['20세 이하', '40세 이하', '60세 이하', '80세 이하', '80세 초과'])데이터프레임 결합
- pd.concat(): 매핑기준은 인덱스(행), 컬럼이름(열)이다.
- pd.merge(): 매핑기준은 특정 컬럼의 값 기준으로 결합한다(데이터베이스 테이블 조인과 같음).
pd.concat()
- 문법: pd.concat([df1, df2, ..., dfn], join=' ', axis= )
a = pd.DataFrame({'A' : [1, 2],
'B' : [15, 30],
'C' : [20, 25]})
b = pd.DataFrame({'A' : [2, 3],
'D' : [3, 35]})
ab1 = pd.concat([a, b], join='inner', axis=0)
ab2 = pd.concat([a, b], join='outer', axis=0)
ab3 = pd.concat([a, b], join='inner', axis=1)
ab4 = pd.concat([a, b], join='outer', axis=1)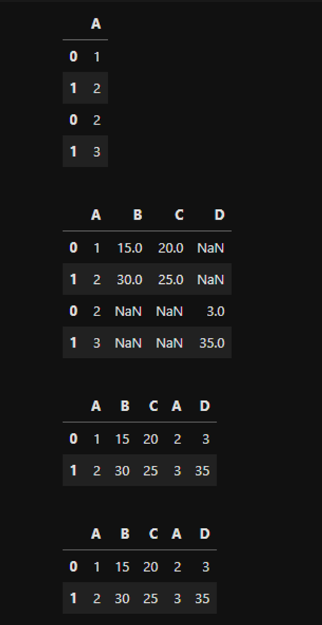
pd.merge()
- 문법: pd.merge(df1, df2, how=' ' )
a = pd.DataFrame({'A' : [1, 2],
'B' : [15, 30],
'C' : [20, 25]})
b = pd.DataFrame({'A' : [2, 3],
'D' : [3, 35]})
ab1 = pd.merge(a, b, how='inner')
ab2 = pd.merge(a, b, how='outer')
ab3 = pd.merge(a, b, how='left')
ab4 = pd.merge(a, b, how='right')
시계열 데이터 처리
- 시계열 데이터: 행과 행에 시간의 순서가 있고, 시간간격이 동일한 데이터
cf) Time Series Data ⊂ Sequentail Data - 날짜 타입으로 변환하기
data['Date'] = pd.to_datetime(data['Date'])- 날짜로부터 의미있는 요소를 뽑아서 사용하기

rolling() + 집계함수
# 7개 Amt값(위 6개, 동일 행 1개)의 평균을 구해서 Amt_MA7_1열에 추가한다.
temp['Amt_MA7_1'] = temp['Amt'].rolling(7).mean()
# 값이 7개가 안되면 NaN이 아닌, 1개이상의 값(min_periods로 설정가능)이 있으면 평균 구하기
temp['Amt_MA7_2'] = temp['Amt'].rolling(7, min_periods=1).mean()shift()
시계열 데이터에서 시간의 흐름 전후로 정보를 이동시킬 수 있다.
temp['Amt_lag'] = temp['Amt'].shift(2) # 인자로 음수도 가능!diff() (차분)
특정 시점 데이터, 이전 시점 데이터와의 차이
# salesY열의 n번째 행과 n-1번째 행의 값을 빼서 Sales_diff1의 n번째 행에 저장
temp['Sales_diff1'] = temp['SalesY'].diff()NaN(결측치)처리 방법
- NaN이 생긴 행 자체를 삭제
- 이전/이후 값으로 채우기(예측하는 모델링에서는 일반적으로 이후 값은 불러오지 않는다).
- 이전, 이후 값의 평균으로 채우기
- 0으로 채우기
결론적으로, 비즈니스 지식과 경험에 의해 결정한다.
데이터 분석 방법론
이제는 조금 다른 이론을 다뤘다. 앞에서는 Pandas활용법이라고 볼 수도 있겠지만 데이터 분석 방법론은 조금 이론적인 이야기이다.
데이터 분석 방법론은 "무엇이 문제인가?"에서 시작해서 "문제가 해결되었는가?"로 끝난다.
- Business Understanding - 가설 수립
- 문제를 정의하고 요인을 파악하기 위해서 가설을 수립한다(귀무가설, 대립가설)
x -> y ( x: 환율, 다우지수, 코스피 / y: 내일주가, 고객이탈여부 등) - 데이터 분석 방향, 목표를 결정한다.
- 문제를 정의하고 요인을 파악하기 위해서 가설을 수립한다(귀무가설, 대립가설)
- Data Understanding
- 데이터 탐색: EDA(탐색적 데이터 분석), CDA(확증적 데이터 분석)
- EDA: 그래프, 통계량을 계산
- CDA: 가설검정을 이용해 가설이 맞는지 확인한다.
- 데이터 탐색: EDA(탐색적 데이터 분석), CDA(확증적 데이터 분석)
- Data Preparation
- Modeling
02.27 - 데이터 처리(2)
시각화 라이브러리
| 함수명 | 기능 |
| plt.plot(color=' ', linestyle=' ', marker=' ') | 기본 라인차트를 그려줌(그래프 색, 라인 스타일, 마커 디자인 변경 가능) |
| plt.show() | 그래프 그리기 |
| plt.xticks(rotation=각도) | x축 값 각도 조정하기 |
| plt.xlabel() / plt.ylabel() | 축 레이블 붙이기 |
| plt.title() | 그래프 타이틀 붙이기 |
| plt.legend(loc=' ') | 범례추가, loc는 범례 위치 설정 |
| plt.grid() | 눈금선 추가 |
| plt.figure(figsize(a, b)) | 그래프 크기 조절, a와 b는 정수이고 plt.figure()은 코드 가장 처음에 실행시켜야 한다. |
| plt.subplot(row, column, index) | row, column만큼 틀을 만들고 index번째에 해당 그래프 위치 |
예제코드
# 첫번째 그래프
plt.plot(data['Date'], data['Ozone'],
color='green', linestyle='dotted', marker='o', label='Ozone')
# 두번째 그래프
plt.plot(data['Date'], data['Temp'],
color='r', linestyle='-', marker='s', label='Temp')
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.legend()
plt.grid()
# 위 그래프와 설정 한꺼번에 보여주기
plt.show()단변량 분석(숫자형)
숫자형 변수를 정리하는 방법
- 숫자로 요약하기: 정보의 대푯값
- 평균(산술평균, 기하평균, 조화평균): 이상치에 의해 왜곡될 수 있다. 데이터가 정규분포형을 띨 때 평균이 대표성을 띤다.
- 중앙값: 자료의 순서상 가운데 위치한 값
- 최빈값: 자료 중에서 가장 빈번한 값
- 사분위수: 데이터를 오름차순으로 정렬한 후 전체를 4등분하고 각 경계에 해당되는 값(25%, 50%, 75%)을 의미
- 구간을 나누고 빈도수 계산
ex) 10대: 1명, 20대: 10명, 30대: 3명 ...
숫자형 변수 시각화 하기 - Histogram
- 코드로 히스토그램 그리기
import matplotlib.pyplot as plt
plt.hist(titanic['Fare'], bins=30, edgecolor='gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()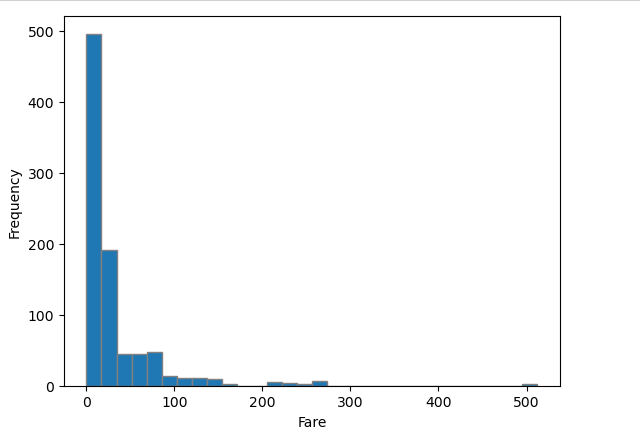
- 해석하기
- 해석1(보이는대로 분석): 대부분의 탑승객은 $30이내에 탑승했고, 극소수의 사람들이 $200 이상이다.
- 해석2(비즈니스적인 추론): 당시 1910년대의 $1는 현재의 약 100~200배 가치이다. 탑승객 대부분은 중산층으로 아메리칸 드림을 꿈꾸며 전 재산을 들고 미국으로 직업을 찾아 이주하려는 사람일 것이다.
- 해석2가 "데이터 분석"이다. 이를 위해서는 도메인 지식이 필요하다!!
- 그래프 읽는 법
- 축의 의미 파악하기: x축, y축이 무엇인지 파악하기
- 데이터의 밀집구간과 희박구간을 파악하기
- 밀집구간과 희박구간이 나타난 이유를 파악하기 -> 이에 대한 비즈니스 의미 파악
숫자형 변수 시각화 하기 - BoxPlot
- 코드로 박스플롯 그리기(NaN값이 있으면 해당 데이터를 처리 후 그려야 한다)
plt.boxplot(titanic['Age'])
plt.grid()
plt.show()
- 해석하기
- 20대~30대가 전체 50%를 차지한다.
- 40세 이하가 전체의 75%이상을 차지한다.
- 중앙값은 약 28세이다.
- 그래프 읽는 법
- 박스부분이 25%~75%부분이다. 즉 전체 50%를 차지하는 부분이다. 박스가 시작하는 부분이 Q1(25%), 노란선이 Q2(50%), 박스가 끝나는 부분이 Q3(75%)이다.
- 수염의 길이는 1.5 * IQR(3사분위수 - 1사분위수)범위내에서 최소값, 최대값이다.
- Fence(1.5 * IQR)밖에 있는 점: 이상치(Outlier)
단변량 분석(범주형)
범주형 변수 숫자로 요약하기
titanic['Embarked'].value_counts()
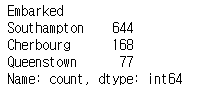
cf) df.value_counts(normalize=True)를 하게되면 범주별 비율이 나온다.
범주형 변수 시각화: Bar Plot
sns.countplot(titanic['Pclass'])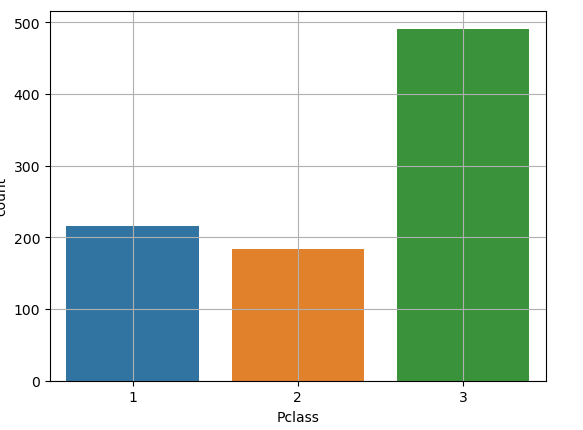
- 막대그래프 vs 히스토그램
| 막대그래프 | 히스토그램 |
| 범주형 데이터 | 연속형 데이터 |
| x순서를 바꿔도 상관이 없다. | x순서를 바꾸면 큰일 난다. |
02.28 - 데이터 분석 및 의미찾기(1)
데이터 분석 및 의미찾기를 주제로한 수업은 통계학 내용이 약간 포함되어 있어 난이도가 조금 있었지만,,, 한 번 정리를 해봤다.
가설검정
- 모집단(Population): 우리가 알고 싶은 대상 전체 영역
- 표본(Sample): 모집단의 일부 영역
- 표본 집단을 조사한다 -> 표본조사
- 표본으로 모집단의 정보를 알고싶은 것이다!!
- 모집단에 대한 가설을 세우고 표본으로 가설이 정말 그러한지 검정(검증)하는 것임.
- 귀무가설과 대립가설
- 귀무가설: 기존에 있던 가설, 우리가 세운 가설에 반대되는 가설(H0)
ex) 타이타닉 생존율은 성별과 관련이 없다. - 대립가설: 기존에 있던 가설에 반대되는 가설, 우리가 세운 가설(H1)
ex) 타이타닉 생존율은 성별과 관련이 있다. - 생존율 차이가 얼마나 있어야 관련이 있는 것인가? => p-value계산
- 0.05보다는 p-value가 작아야 차이가 있다고 판단하고 차이 값이 클수록 p-value는 작아진다.
- 귀무가설: 기존에 있던 가설, 우리가 세운 가설에 반대되는 가설(H0)
이변량 분석 1 : 숫자 → 숫자

시각화: 산점도
# 온도와 오존 양의 관계
plt.scatter(air['Temp'], air['Ozone'])
plt.show()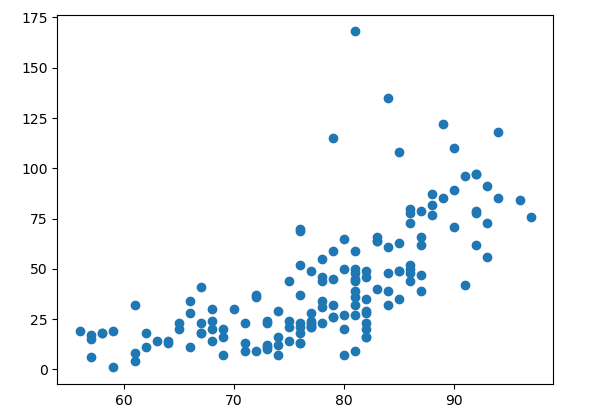
이 때, 직선이 보이는가? 가 중요하다!
위 그래프에서는 우상향하는 직선이 보일 것이다.

얼마나 직선에 접들이 모여있는지로 관련성이 있는지 파악할 수 있다.
수치화: 상관분석
- 상관계수: 관계를 수치화한 것
- 상관분석: 상관계수가 유의미한지를 검정하는 것
imprt scipy.stats as spst
spst.pearsonr(air['Temp'], air['Ozone'])
# 주의사항: 상관계수를 구하기 전 NaN값은 처리를 해야한다.
상관계수가 0.68, p-value는 거의 0에 수렴하는 값이 나왔다.
- 상관계수(r) 기준(정답은 아님)
- 강한 상관관계: 0.5 < | r | <= 1
- 중간 상관관계: 0.2 < | r | <= 0.5
- 약한 상관관계: 0.1 < | r | <= 0.2
- (거의) 관계 없음: | r | <= 0.1
따라서, p-value가 0에 수렴하므로 대립가설(온도는 오존에 영향을 준다)을 채택할 수 있다. 그리고 상관계수는 0.68로 temp와 ozone은 강한 상관관계를 가지고 있다고 판단할 수 있다.
이변량 분석 2 : 범주 → 숫자
feature가 범주형이고 target이 숫자(수치)형이면 평균비교이다!! 일반적으로 표본의 평균이 모집단의 평균과 95%신뢰수준에서 같을 것이다라는 가정을 세우고 분석한다.
시각화: barplot
sns.barplot(x='Survived', y='Age', data=titanic)
plt.grid()
plt.show()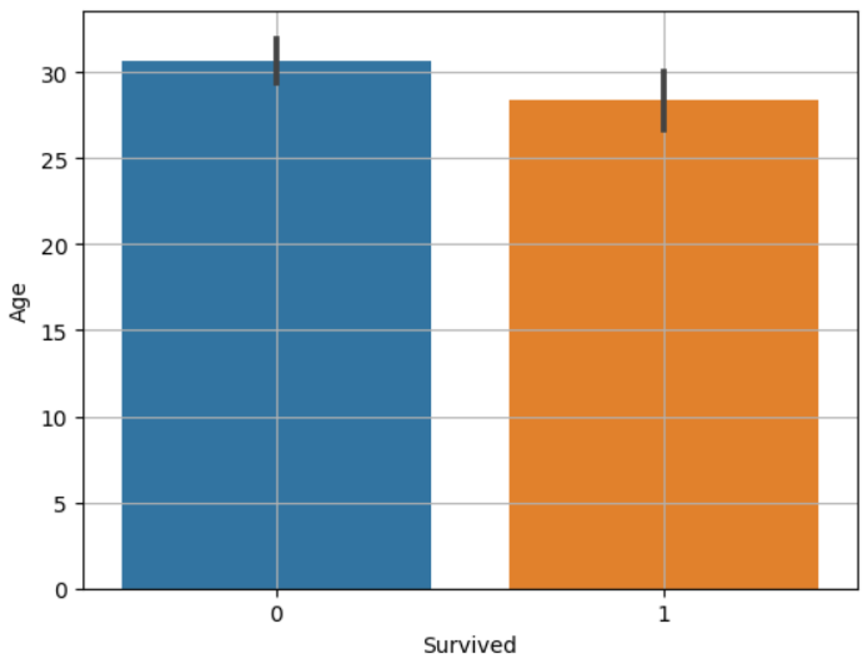
- 검은색 바: 95% 신뢰구간을 의미
- 두 평균의 차이가 크고 신뢰구간(검은색 바)이 겹치지 않을 때, 대립가설이 맞다고 판단한다. 위 예시는 대립가설을 기각(귀무가설 채택)한다.
수치화: t-test, anova(분산분석)
- 범주가 2개일 때: t-test
- 범주가 3개 이상일 때: anova(생략)
died = titanic.loc[titanic['Survived'] == 0, 'Age']
survived = titanic.loc[titanic['Survived'] == 1, 'Age]
spst.ttest_ind(died, survived)
- t 통계량이 -2보다 작거나 2보다 크면 차이가 있다고 본다. 이 때, p-value값도 0.05보다 작아야한다.
02.29 - 데이터 분석 및 의미찾기(2)
이변량 분석 3 : 범주 → 범주
시각화: mosaic plot
from statsmodels.graphics.mosaicplot import mosaic
mosaic(titanic, ['Pclass', 'Survived'])
plt.axhile(1 - titanic['Survived'].mean(), color='r')
plt.show()
- 붉은색 선은 생존자의 평균이다. 붉은색 배경은 3등급 사람의 생존율이다. 즉, 평균보다 생존율이 낮음으로 알 수 있다. 1등급 사람은 평균보다 생존율이 높고, 2등급 사람은 평균보다 다소 높은 모습을 볼 수 있다. 두 범주가 아무런 상관이 없다면, 평균(붉은선)과 모든 변수가 동일한(혹은 근사한 차이) 그림이 나올 것이다.
수치화: 카이제곱 검정
- x와 y가 독립적일 때 기대되는 값과 실제 관측된(측정된) 값들의 차이가 적은지, 큰지를 확인하는 것
- 카이제곱 계산 법

즉, 카이제곱값이 클수록 x와 y가 독립적이지 않다는 의미이다. 즉, 상관관계가 존재한다.
# 교차표 집계
table = pd.crosstab(titanic['Survived'], titanic['Pclass'])
# 카이제곱 검정
spst.chi2_contingency(table)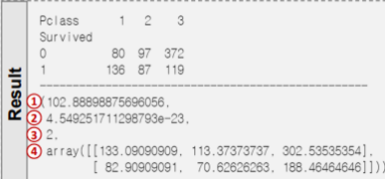
1. 카이제곱 통계량
2. p-value
3. 자유도
4. 기대빈도
=> 일반적으로, 자유도보다 2배 큰 값이면 차이가 있다고 본다(대립가설을 채택한다). 위 예시에서는 자유도가 2이고 카이제곱통계량이 102이므로 대립가설을 채택할 수 있다.
이변량 분석 4 : 숫자 → 범주
시각화: kdeplot(Kernel Density Estimate)
sns.kdeplot(x='Age', data=titanic, hue='Survived', common_norm=False)
plt.show()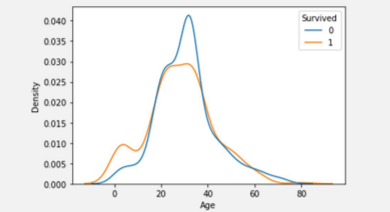
- 생존여부 각각 아래 면적의 합이 1이다. 즉, 파란색 면적도 1, 주황색 면적도 1이다.
- 생존자와 사망자가 겹치는 구간이 5군데가 있는데 이 부분이 생존율 평균과 같은 부분이다.
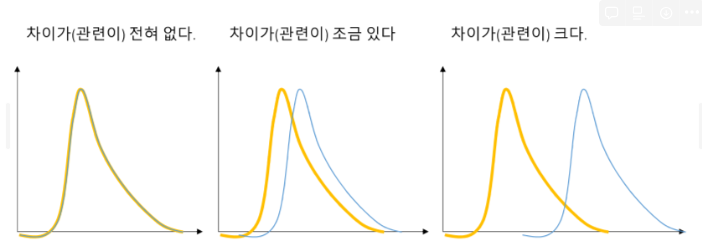
만약, 파란색선과 주황색선이 완전히 겹치면 생존율과 나이는 전혀 관련이 없다고 판단할 수 있다.
comments
좀 늦은 2주차 후기가 되었다. 주말에 개인적인 일정이 있는 관계로,,, 1주차에는 파이썬 문법과 numpy, pandas 등 조금은 기초적인(?) 내용들이 주가 되었다면 2주차에는 데이터 분석이 주 내용이었다. 이 내용을 바탕으로 미니프로젝트를 한다는데 걱정이 된다.(사실 지금 미프 끝나고 글을 쓰는거긴 하다ㅋ) 하지만 긍정적인면은 데이터 분석에 그래도 조금의 흥미를 느꼈고 에이블스쿨이 생각보다 힘들지는 않다는 것이다. 아, 그리고 부전공으로 들었던 "통계학"이 여기에서 쓸모가 있을줄은 몰랐다. 그래도 통계는 어렵지만,,, 3주차에는 미니프로젝트와 웹크롤링 수업이 있는데 차주에도 열정적으로 참여해야겠다! 끝으로, 좋은 강의 들려주신 한기영 강사님께 감사드린다.
'Study > KT AIVLE School' 카테고리의 다른 글
| [KT AIVLE School] AI 트랙 4주차 후기 (머신러닝) (0) | 2024.03.17 |
|---|---|
| [KT AIVLE School] AI트랙 3주차 후기 (미니프로젝트, 웹크롤링) (2) | 2024.03.10 |
| [KT AIVLE School] AI트랙 1주차 후기 (1) | 2024.02.25 |
| (사전교육)[KT AIVLE School] 데이터 선택 (2) | 2024.02.04 |
| (사전교육)[KT AIVLE School] 개발환경 세팅 (0) | 2024.02.03 |



