
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 에이블스쿨6기
- 내일배움카드
- jupyter notebook
- 에이블스쿨
- 자연어처리
- 에이블데이
- KT
- keras
- Anaconda
- Aivle school
- 코딩테스트
- KT AIVLE SCHOOL
- 내배카
- 딥러닝
- Python
- KT wiz
- pandas
- 부트캠프
- 해외연수
- kaggle
- sklearn
- KT에이블스쿨
- numpy
- YOLO
- 미니프로젝트
- AIVLE
- 한국외대
- HUFS
- AIVEL
- AI
- Today
- Total
Hyunn
[KT AIVLE School] AI 트랙 4주차 후기 (머신러닝) 본문
4주차 일정
03.11 ~ 15 : 머신러닝
이번 후기부터는 날짜별이 아닌, 주제별로 정리해보려고 합니다.
금주에는 이장래강사님이 머신러닝이라는 주제로 강의를 해주셨다. 컴퓨터공학을 전공했지만 머신러닝은 처음이라 조금 두려움 반 기대 반으로 시작했다.
머신러닝이란?
입력 값(x, feature)를 토대로 학습을 해서 패턴을 찾아 y값을 예측하는 것!
머신러닝의 종류
| 지도학습 | 정답이 있는 데이터를 머신에게 제공해서 규칙성을 찾게 하는 것 |
| 비지도학습 | 정답이 없는 데이터를 머신에게 제공해서 규칙성을 찾게 하는 것 예시) 고객을 4개 그룹으로 나누기(클러스터링) |
| 강화학습 | 보상을 통해 계속 학습하는 방법 |
용어 정리
| 모델 | 데이터에서 패턴을 찾아 수식으로 정리해 놓은 것 |
| 샘플 | 표본, 부분집합, x데이터의 일부 |
| 열 | 변수, Feature |
| 행 | 관측치, 인스턴스 |
| 독립변수 | 결과에 영향을 미치는 변수(Feature)들 (y = ax + b에서 x가 독립변수) |
| 종속변수 | 독립변수에 의해 결정되는 변수(target) (y = ax + b에서 y가 종속변수) |
| 가중치 | y = ax + b에서 a가 가중치 |
| 편향 | y = ax + b에서 b가 편향(절편) |
| 오차 | 실제 값과 모델 예측값의 차이 |
| 과대적합(Overfiting) | 학습 데이터에 대해서만 잘 맞는 모델(모델이 너무 복잡함) |
| 과소적합(Unerfitting) | 학습 데이터도 학습을 하지 못한 모델(모델이 너무 단순함) |
분류와 회귀
- 분류(Classification): 0과 1로 분류하는 것, 즉 범주값을 예측하는 것이다.
예시) 공부시간에 따른 합격 여부(합: 1, 불: 0)를 예측하기
- 회귀(Regression): 근사치 값을 예측하는 것, 즉 연속적인 숫자를 예측하는 것
예시) 공부시간에 따른 시험 점수(0 ~ 100) 예측하기
cf) 수치형인지 범주형인지 살펴보는 방법은 중간값이 의미있는 수인지 확인하는 것이다. 예를들어, 합격여부에서 0.5는 합격도 아니고 불합격도 아닌 의미없는 값인 반면에 시험점수에서 50은 50점이라는 의미있는 값이다.
코드 구조
강사님 말씀으로는 먼저 개념을 알기 전 무작정 코드를 따라해보는게 좋다고 하셨다. 처음에는 의아했지만 코드를 작성해보고 결과를 확인한 후에 어떤 원리인지 공부하는 것도 괜찮은 순서라는 생각이 들었다.
- 필요한 모듈 불러오기
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metric import mean_absolute_error - 데이터 확인하기
data = pd.read_csv(path) data.head() data.tail() data.describe() data.info() data.corr(numeric_only=True)
이 외에도 다양한 방법으로 어떤 데이터인지 확인하는게 중요하다! - 데이터 전처리하기 및 feature와 target으로 나누기
# 사용하지 않는 열 drop하기 drop_cols = [] data.drop(dumm_cols, axis=1, inplace=True) # x, y분리 target = ' ' x = data.drop(target, axis=1) y = data.loc[:, target] # 가변수화 dumm_cols = [] x = pd.get_dummies(x, columns=dumm_cols, drop_first=True) - 훈련데이터, 평가데이터 나누기
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1) - 모델 훈련하기
# 모델 선언 model = KNneighborRegressor() # KNN모델이라고 가정 # 모델 학습 model.fit(x_train, y_train) - 예측 및 검증하기
y_pred = model.predict(x_test) print(clssification_report(y_test, y_pred)) print(confusion_matrix(y_test ,y_pred))
모델 평가 방법
- 회귀모델: MAE, MSE, R2-score etc.
- MAE: Mean Absolute Error: 실제값에서 예측값을 빼고 절대값을 씌운 값들의 평균
- MSE: Mean Squared Error: 실제값에서 예측값을 빼고 제곱을 한 값들의 평균
- SSR: 예측값과 평균 차이의 제곱의 합
- SST: 실제값과 평균 차이의 제곱의 합(평균의 오차 합)
- SSE: 실제값과 예측값 차이의 제곱의 합(예측값의 오차 함)
- R2-Score: 전체 오차 중에서 회귀식이 잡아낸 오차 비율(클수록 성능이 좋음)
예시) r2-score가 0.8일 때, 우리 모델이 평균에 비해서 80%정도 더 효과가 있는 모델이라는 의미
식) SSR / SST = 1 - SSE/SST
- 분류모델: confusion matrix, recall, accuracy etc.
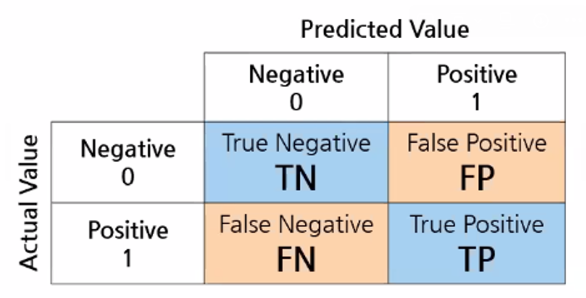
- Recall(민감도): 실제 True인 값을 True라고 예측한 비율
- Precision(정밀도): True라고 예측한 값 중에서 실제 True인 값의 비율
- Accuracy(정확도): 실제 True와 False를 맞춘 정도
- 특이도: 실제 False중에서 False로 예측한 비율
- f1-score: recall과 precision의 조화평균
정확도가 높다고 해서 좋은 모델이라고 단정지울 수는 없다. 예를들어, 우리나라에서 지진발생 여부를 예측해본다면, 항상 발생하지 않는다고 예측하면 정확도는 99%이상일 것이다. 하지만 Recall은 0이 될 것이다. 따라서 정확도, 민감도, 정밀도를 확인해야한다.
모델 종류 및 알고리즘
Linear Regression(회귀)
- 데이터의 패턴을 찾아 함수 식으로 표현하는 것
- 단순회귀: 독립변수 하나가 종속변수에 영향을 미치는 선형회귀
- 다중회귀: 여러 독립변수가 종속변수에 영향을 미치는 선형회귀
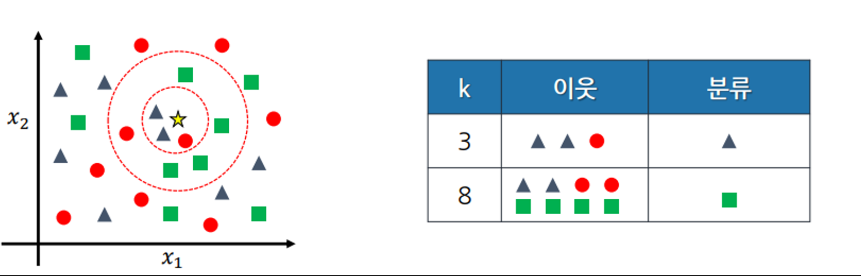
K-Nearest Neighbor(분류, 회귀)
- 가까운 이웃 k개를 묶어 이웃들의 결과를 보고 자신의 결과를 예측하는 것
- 가장 적절한 k값을 찾는 것이 중요하다
- 일반적으로 k는 홀수이다.
- 가까운 이웃을 구하는 방법은 거리를 구하는 것인데, 유클리드 거리와 맨허튼 거리가 있다. 파라미터를 통해 어떤 거리를 사용할지 결정할 수 있다.
- x1축과 x2축의 데이터 크기가 다를 수 있기 때문에 정규화(모든 변수를 0과 1사이로 만드는 작업)가 필요하다.
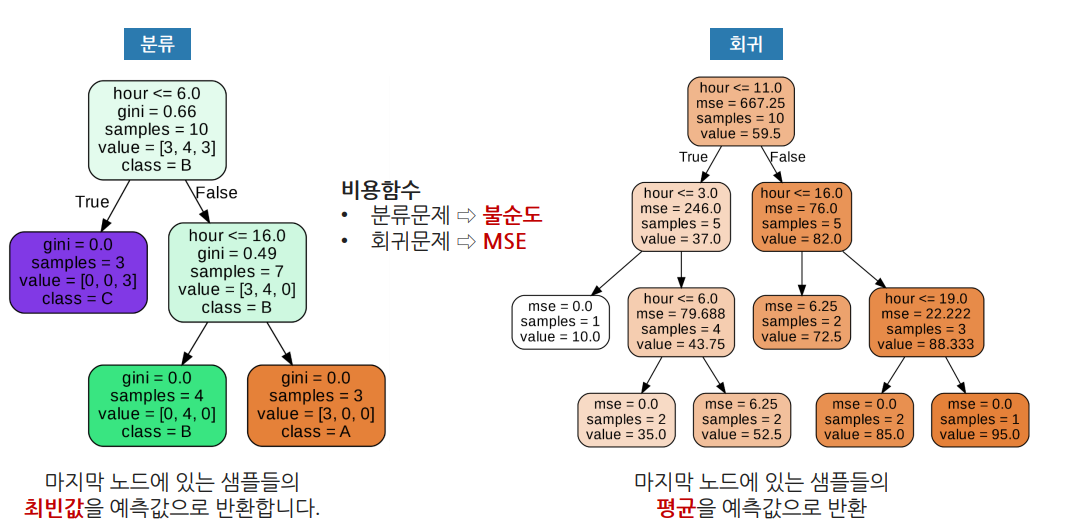
Decision Tree(분류, 회귀)
- 특정 조건으로 데이터를 나누는 방식
- 과적합이 발생할 가능성이 높다.
- 분석과정을 눈으로 확인할 수 있다(화이트박스 성질).
- 트리 깊이(max_depth)를 제한하는 튜닝이 필요함
용어 정리
| Root node | 가장 위에 있는 노드 |
| Terminal node | 자식이 없는 노드 |
| Internal node | 부모노드와 자식노드가 모두 있는 노드 |
| Depth | 루트노드로부터 끝 노드까지의 연결된 마디 개수 |
그래프 보기

- Petal.Length<=2.6: 질문부분, 위 예시에서는 'Peta.Length가 2.6이하인가?'로 True, False로 나누는 것
- gini: 지니 불순도(값이 낮을수록 순도가 높은 것)
- samples: 데이터 샘플의 개수
- value: 세 품종의 개수
- class: 가장 많은 품종, 위 예시에서는 virginica가 가장 많음
Logistic Regression(분류, 회귀)
- 분류문제도 회귀식을 통해 예측하는 알고리즘
- 로지스틱 함수
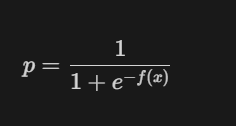
- f(x)는 선형 판별식이다. 이 식이 양의 무한대로 가는 경우 p는 1에 가까워지고, 음의 무한대로 가는 경우에는 p값은 0에 가까워진다.
- 기본적으로 0.5를 기준으로 이보다 크면1, 작으면 0으로 분류한다. 이 임계값은 상황에 따라 바꿀 수 있다.
예시) 0.5 이상이면 암, 미만이면 암이 아니다라고 판단했는데, rcall을 높이고 싶으면 0.4정도로 낮출수도 있다. 반대로 보수적으로 판단하려면 0.6정도로 높일수도 있다.
Ensemble Algorithm(분류, 회귀)
- 약한 모델을 여러개 모아서 다수결 판다에 따르는 알고리즘
- 앙상블 알고리즘은 보팅, 배깅, 부스팅, 스태킹 방식으로 나뉜다.
보팅(Voting)
예를들어 Decision Tree는 1로 예측, KNN은 0으로 예측, Logistic Regression도 0으로 예측했다.
이런경우 하드보팅은 0으로 예측하고 소프트보팅은 0일 확률이 66.6%로 예측한다.
배깅(Bagging)
이것도 에를들어, 무작위 샘플링한 데이터로 학습한 Decision Tree모델 3개가 있는데 이것들의 예측값을 다수결로 결정하는 알고리즘이다. 즉, 같은 알고리즘 모델들의 다수결 예측값이다. 대표적인 알고리즘은 랜덤 포레스트가 있다.
부스팅(Boosting)
이전 모델이 제대로 예측하지 못한 데이터에 대해서 가중치를 부여하여 다음 모델이 학습과 예측을 하는 방법(과적합 발생 가능성이 있음). 대표적인 알고리즘은 XGBoost, LightGBM이 있다.
스태킹(Stacking)
기본 모델들을 만들고, 기본 모델에서 나온 예측값들을 모아, 최종 모델이 최종적으로 예측한 값이 결과가 된다.
K-Fold Cross Validation
데이터를 학습용, 검증용, 평가용으로 나누어 훈련용, 검증용 데이터에 대해 해당 모델의 정확도가 어느정도 되는지 테스트 할 수 있다. 테스트 결과를 통해서 어떤 모델을 선택하는게 좋을지 판단할 수 있다. 하지만 훈련용 데이터에서 높은 결과가 나온것이 평가에서 높은 결과가 나오는 것을 보장하는 것은 아님!
- 데이터를 학습용(x_train)과 평가용(x_test)로 나눈다.
- 학습용에서 학습용과 검증용으로 나눈다.
- 반복해서 학습, 검증을 하고 최종 정확도를 구한다.
- 평가용으로 평가를 한다.
즉, 모든 데이터가 평가에 1번, 학습에 k-1번 사용된다.
- 장점
- 조금 더 일반화된 모델을 만들 수 있음
- 모든 데이터를 학습과 평가에 사용할 수 있음
- 어떤 알고리즘이 적절한지 알 수 있음(100% 정확하지는 않음)
- 단점
- 반복횟수가 많아서 모델 학습과 평가에 많은 시간이 소요된다.
Hyperparameter 튜닝
: 모델 성능을 최적화하기 위해 조절하는 매개변수를 의미한다. 튜닝하는 방법은 지식과 경험, 다양한 시도를 통해...
KNN알고리즘의 성능을 조절하는 매개변수
- k값: k가 클수록 모델이 단순해지고, 작을수록 복잡해진다.
- 거리 계산법: 유클리드 거리와 맨허튼 거리 계산 방법이 있다. 맨허튼 거리가 유클리드 거리보다 항상 크거나 같다.
Decision Tree알고리즘의 성능을 조절하는 매개변수
- max_depth: 어디까지 데이터를 분류하는지 결정하는 매개변수이다. default값은 끝까지 뻗어나간다. 값이 클수록 모델이 복잡해지고 작을수록 단순해진다.
- min_samples_leaf: leaf가 되기 위한 최소한의 데이터 수이다. 값이 클수록 모델이 단순해지고 작을수록 모델이 복잡해진다.
- min_samples_split: 분할하기 위한 최소한의 샘플 데이터 수이다. 값이 클수록 모델이 단순해지고 작을수록 복잡해진다.
Grid Search & Random Search
Grid Search는 특정 파라미터 범위를 지정하면 모든 경우를 테스트 하는 방식이고 Random Search는 특정 파라미터 범위 중 랜덤하게 값을 지정해서 테스트하는 방식이다. 당연히 Grid Search는 많은 시간이 소요되지만 정확하고 Random Search는 적은 시간이 소요되지만 정확하지 않을 수도 있다.
Comments
코드를 적지도 않았는데 개념만으로도 정말 많은 내용을 배웠다. 컴퓨터공학과를 졸업했지만 인공지능 관련된 수업은 데이터마이닝, 자연어처리 이 두 수업밖에 듣지 않았지만, 머신러닝 수업의 대부분 내용을 충분히 이해할 수 있었다. 하지만 내용이 많아 복습은 필수일 것 같다...! 다음주에 있는 딥러닝 수업도 기대가 된다. 벌써 에이블스쿨 한 달이 되었는데 이런 속도면,,, 금방이겠는걸. 후회가 되지 않는 시간을 보내자..
'Study > KT AIVLE School' 카테고리의 다른 글
| [KT AIVLE School] AI트랙 7주차 후기(시각지능 딥러닝) (0) | 2024.04.10 |
|---|---|
| [KT AIVLE School] AI트랙 5 & 6주차 후기(딥러닝) (2) | 2024.04.02 |
| [KT AIVLE School] AI트랙 3주차 후기 (미니프로젝트, 웹크롤링) (2) | 2024.03.10 |
| [KT AIVLE School] AI트랙 2주차 후기(데이터 처리, 데이터분석 및 의미찾기) (0) | 2024.03.06 |
| [KT AIVLE School] AI트랙 1주차 후기 (1) | 2024.02.25 |



