
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 딥러닝
- AIVEL
- 내배카
- Anaconda
- KT에이블스쿨
- KT
- kaggle
- Python
- 미니프로젝트
- HUFS
- 에이블스쿨
- YOLO
- 자연어처리
- KT AIVLE SCHOOL
- AI
- 코딩테스트
- 부트캠프
- KT wiz
- 내일배움카드
- jupyter notebook
- sklearn
- 에이블스쿨6기
- Aivle school
- 에이블데이
- keras
- numpy
- 해외연수
- pandas
- 한국외대
- AIVLE
- Today
- Total
Hyunn
[KT AIVLE School] AI트랙 7주차 후기(시각지능 딥러닝) 본문
7주차 일정
04.01 ~ 04.05 : 시각지능 딥러닝

금주는 시각지능 인공지능인 CNN, YOLO, Transfer Learning에 대해 배웠다.
CNN(Convolutional Neural Network)
CNN은 기존 FC(Full Connected Layer)와는 다르게 이미지의 위치정보를 포함하여 학습하는 방법이다. FC는 이미지 정보를 Flatten하게 1차원 데이터로 만들어 학습했다면 CNN은 3차원의 정보를 filter를 이동하며 학습한다.
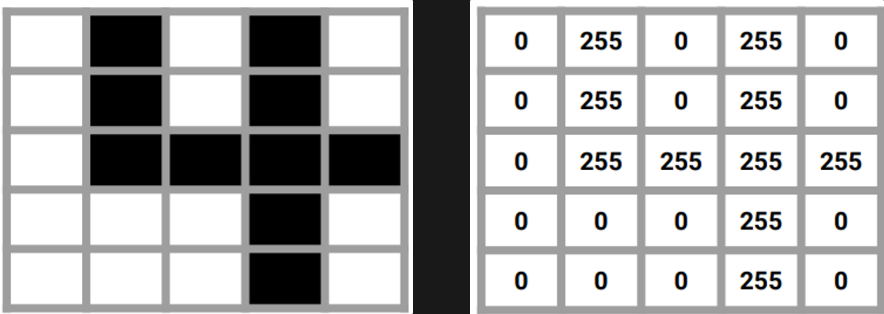
컴퓨터는 왼쪽 그림을 오른쪽과 같이 이해한다. 즉 0 ~ 255값을 이용해 이미지를 표현한다. 해당 이미지를 학습할 때는 filter를 이동하며 feature map을 만들어간다.
- filter: 이미지를 학습할 때 쓰이는 행렬의 크기. 예를들어, filter의 사이즈가 2X2일 때, 1번째 특징을 찾는 과정은 [[0, 255],[0, 255]]가 되며 2번째는 [[255, 0], [255, 0]]이 된다. 즉 상하좌우로 한 칸씩(이 또한 strides값에 따라 달라질 수 있음) 이동하며 이미지의 특징을 찾아내는 과정이다.
- feature map: filter가 이동하며 만든 행렬. 예를들어, 2X2크기의 filter가 이동하며 feature map을 만들 때, 랜덤한 값의 행렬과 filter가 보고있는 값을 곱해 만든다. 랜덤한 행렬이 [[1, 0], [0, 1]]이라면, [[0, 255],[0, 255]]값과 곱하여 그 합을 feature map의 첫 번째 위치에 적는다. 그림으로 표현하면 아래와 같다.
- Strides: filter가 이동하는 보폭을 의미한다. strides가 (2, 2)라면 가로세로 2칸씩 이동하며 feature map을 만든다.

Padding
Padding은 filter가 이동하며 feature map을 만들 때, 외곽정보는 반영하지 않는다는 문제점이 발생해 feature map의 가장자리에 0을 채워 넣어 가장자리도 filter가 여러번 훑을 수 있다.
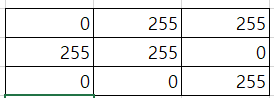
위와 같은 feature map이 있으면 아래와 같이 가장자리에 0을 붙여넣는 것이다.
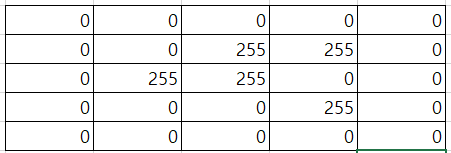
또한, padding을 한다면 다음 layer에서 이전 feature map의 크기와 같은 크기의 feature map을 만들 수 있다.
즉, padding의 목적은 두 가지로, (1) 외곽정보를 더 반영하기 위함, (2) feature map의 크기를 유지하기 위함 이다.
Pooling
Pooling은 feature map의 크기를 줄이기 위한 기법이다. feature map이 크면 그만큼 연산량이 많아지므로 이미지를 학습하는데 오랜 시간이 걸린다. 따라서 최대한 이미지의 특징은 유지하면서 크기를 줄일 수 있는 방법이다. pooling은 filter를 이동하며 filter안에 있는 값 중 대푯값으로 feature map을 재구성하는 한다.
- Max pooling: filter안에 있는 행렬 중 가장 큰 값을 feature map에 저장
- Average pooling: filter안에 있는 행렬의 평균을 feature map에 저장
CNN 이해하기
CNN은 위에서 설명한 기법을 Layer로 쌓아 학습하는 딥러닝 방법이다.
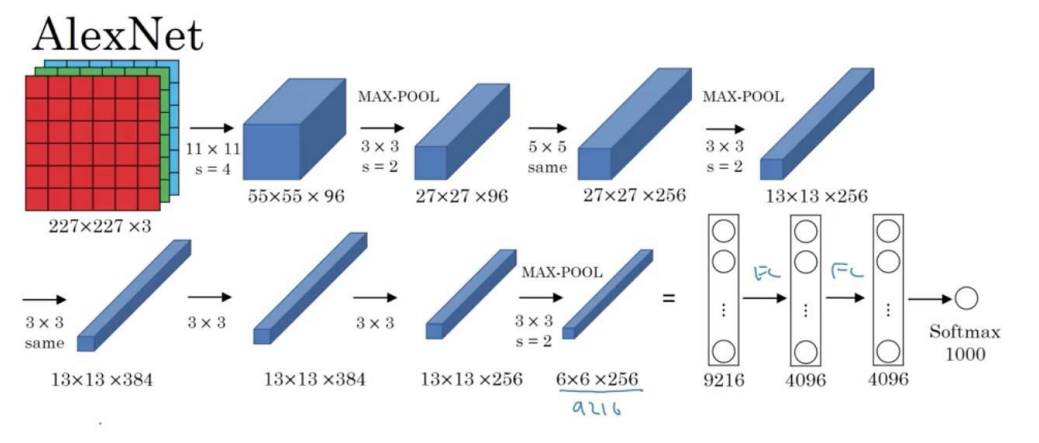
[Feature map 만들기]
Input 이미지가 (227, 227, 3)이라고 하자. 227, 227은 이미지의 크기이다. 즉, 해상도를 의미한다. 3은 r, g, b를 의미한다. 즉, 컬러 이미지임을 알 수 있다. 참고로 흑백은 1이다(227, 227, 1). 해당 Input이 11X11크기, strides를 4를 가진 filter를 지났다면 (55, 55, 96)인 feature map이 만들어진다. feature map의 크기를 구하는 식은 아래와 같다.
I는 입력(이전 feature map크기), F는 filter size, P는 padding, S는 strides
$$O = \frac{I - F + 2P}{S} + 1$$
위 예시에서 I는 227, F는 11, P는 0, S는 4이므로 아래와 같이 계산이 가능하다.
$$\frac{227 - 11 + 0}{4}+ 1 = 55$$
그리고, (55, 55, 96)에서 96이 의미하는 것은 filter의 개수이다. 즉, 11 X 11크기의 filter가 96개의 feature map을 만들었다는 의미이다.
추가적으로, filter의 크기를 정확히 표현하자면 (11, 11, 3)이된다. 가장 마지막에 위치한 3은 이전 feature map의 depth와 같아야한다.
[Max Pooling]
(55, 55, 96) 뒤에 있는 feature map은 max pooling을 거친 feature map이다. 3 X 3크기의 filter가 2만큼 보폭을 갖고 feature map의 크기를 줄였다. 이 또한 위 식에 대입하면 쉽게 구할 수 있다.
[Padding 적용]
'same'이라고 적힌 layer를 거친 feature map은 이전 feature map과 크기가 동일한 것을 확인할 수 있다. same padding이 적용된 것이다. 위의 식에 P값에 1을 대입해 계산하면 된다. 하지만 계산할 필요없이 same padding이라면 이전 feature map의 크기를 따라간다고 생각하면 된다.
[Flatten]
Flatten은 CNN으로 되어있는 데이터를 1차원 데이터로 만드는 과정이다. 이미지 학습의 결과의 대부분은 classification이기 때문에 마지막은 Dense layer를 거쳐 output이 도출되어야 한다. 따라서 (6, 6, 256)인 feature map을 Flatten함수를 이용해 평탄화 작업을 하면 9216개의 Node가 생기게 되고 이를 위의 그림에서는 Dense를 이용해 2번 더 학습한 후 softmax activation함수를 통해 output layer를 구성했다.
CNN 코드
# 필요한 모듈 불러오기
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, confusion_matrix
from keras.utils import to_categorical
from keras.layers import Conv2D, Flatten, Batchnormalization, Dense, Input, Maxpool2D
from keras.callbacks import EarlyStopping
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt## x와 y는 이미 가지고 있는 데이터라고 가정
# 1. train데이터와 test데이터 분리하기
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 2. x값 스케일링하기
x_train = x_train / 255.
x_test = x_test / 255.
# 3. y값 one-hot encoding으로 인코딩하기(binary classification이면 생략해도 좋다)
classes = len(np.unique(y_train))
y_train = to_categorical(y_train, classes)
y_test = to_categorical(y_test, classes)
# 4. model 설계하기
model = Sequential()
model.add(Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu')
model.add(Conv2D(filters=64,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu')
model.add(MaxPool2D(pool_size=(2,2),
strides(2,2))
model.add(Batchnormalization())
model.add(Dropout(0.25)
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu')
model.add(Conv2D(filters=128,
kernel_size=(3,3),
strides=(1,1),
padding='same',
activation='relu')
model.add(MaxPool2D(pool_size=(2,2),
strides(2,2))
model.add(Batchnormalization())
model.add(Dropout(0.25)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
모델 설계를 마치고 summary함수를 통해 파라미터, layer 등을 확인할 수 있다.
es = EarlyStopping(patience=5,
monitor='val_loss',
min_delta=0,
verbose=1,
restore_best_weights=True)
model.fit(x_trian, y_train, epochs=10000, validatin_split=.2, callbacks=[es])
pred = model.predict(x_test)
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))
여기까지가 CNN의 기본적인 코드 뼈대이다. 여기서 Conv layer를 변형하거나, 파라미터를 변경할 수 있다.
Data Augmentation
모델을 학습시키기 위해서는 데이터가 많으면 많을수록 좋다. 하지만 현실에서는 데이터가 부족한 경우가 다반사이다. 따라서 Data Augmentation을 통해 데이터를 증강시키거나 다양한 데이터를 만들어서 모델이 다양한 데이터에 대해 학습할 수 있도록 해야한다.
어떤 Augmentation layer가 있는지는 아래 keras 공식문서를 참고하면 좋을 것 같다.
https://keras.io/api/layers/preprocessing_layers/image_augmentation/
사용방법은 기존 layer에 층을 더 쌓으면 된다.
...
il = Input(shape=(28, 28, 1))
al = keras.layers.RandomRotation(factor=(-0.1,0.1))(il)
al = keras.layers.RandomTranslation(height_factor=(-0.1,0.1), width_factor=(-0.1,0.1))(al)
al = keras.layers.RandomZoom(height_factor=(-0.1,0.1), width_factor=(-0.1,0.1))(al)
Conv2D(filters=64,
kernel_size=(3,3),
activation='relu',
padding='same',
strides=(1,1))(al)
...Transfer Learning(전이학습)
: 현실에서는 Data Augmentation을 해도 데이터가 턱없이 부족한 경우들이 많다. 데이터가 부족하면 모델의 가중치 설정이 잘 되지 않으므로 이미 잘 학습되어진 모델을 가져다가 우리가 필요한 모델로 변형(Fine-Tuning)하는 과정을 거쳐 사용하는 것을 말한다.
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.applications.inception_v3 import decode_predictions
keras.backend.clear_session()
base_model = InceptionV3(weights='imagenet', # ImageNet 데이터를 기반으로 미리 학습된 가중치 불러오기
include_top=False, # InceptionV3 모델의 아웃풋 레이어는 제외하고 불러오기
input_shape= (299,299,3)) # 입력 데이터의 형태
new_output = GlobalAveragePooling2D()(base_model.output)
new_output = Dense(3, # class 3개 클래스 개수만큼 진행한다.
activation = 'softmax')(new_output)
model = keras.models.Model(base_model.inputs, new_output)
model.summary()
Object Detection
Object Detection은 이미지에서 특정한 개체를 탐지하는 기술이다. 따라서 두 가지 문제로 볼 수 있다.
Object Detection에서의 회귀문제
먼저 이미지에서 Ojbect의 위치를 알아야한다. 즉, bounding box의 꼭짓점 위치, bounding box의 크기를 알아내는게 관건이다.
- x, y값 예측: bounding box의 꼭짓점을 예측하는 문제
- w, h값 예측: bounindg box의 크기를 예측하는 문제

x, y, w, h를 이용해 CAT이라는 object를 bounding box로 탐지했다. → 회귀문제
Object Detection에서의 분류문제
bounding box안에 있는 개체가 어떤 이미지인지를 판단하는 문제로, 앞의 CNN과 동일한 문제이다.
Confidence Score
: Object가 Bounding box안에 있을 확률을 나타내는 값으로, 0 ~ 1값을 갖는다.

그림에서 초록색 박스는 예측에 성공한 것이고 빨간색 박스는 예측에 실패한 것을 나타낸다. 옆에 있는 숫자가 Confidence score인데 0.95라면 95%확률로 해당 위치에 개체가 있을 확률이고 그 개체는 airplane이라는 의미이다.
IoU(Intersection over Union)
: 실제값과 모델이 예측한 bounding box가 얼마나 겹치는지를 나타내는 지표이며 0 ~ 1값을 갖는다.
실제 값의 bounding box와 예측한 값의 bounding box가 완벽히 겹치면 1, 절반만 겹치면 0.5의 값을 갖는다. 하지만 실제 bounding box를 알지 못하므로 confidence값이 제일 높은 bounding box를 실제 bounding box로 간주하고 IoU를 판단한다. 이에대한 추가설명은 후술하였다.
NMS(Non-Maximun Suppression)
동일 object에 대한 중복된 bounding box를 제거하는 것
- 일정 confidence이하의 bounding box를 제거한다(코드에서 옵션으로 지정 가능).
- 남은 bounding box을 confidence score기준으로 내림차순으로 정렬한다.
- 첫 bounding box와 IoU값이 일정 이상인 박스들을 제거한다(첫 bounding box를 정답으로 간주하고 이와 일정 이상 겹치면 같은 object를 탐지했다고 보는 것이다, 이 또한 코드에서 옵션으로 지정 가능).
- bounding box가 하나가 될 때까지 반복한다.
YOLO v8
Robowflow를 통해 detect된 이미지를 통해 학습하기
rf = Roboflow(api_key=" ... ") # 유저마다 상이함
project = rf.workspace("roboflowex").project("roboflowex2-gwigl")
dataset = project.version(1).download("yolov8")
[yaml파일]
yaml파일은 데이터 셋에 대한 정보(메타데이터)가 포함되어 있다.

- names: 클래스별 이름
- nc: 클래스 개수
- test, train, val: 각 데이터 셋의 경로(올바르게 적어줘야 학습이 됨)
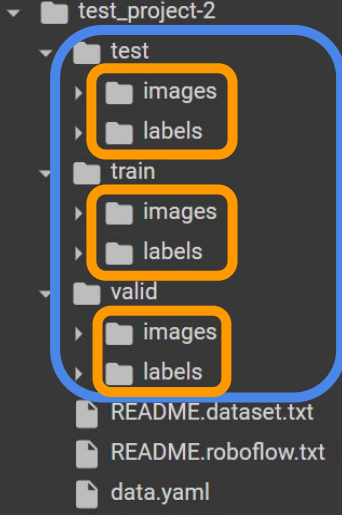
데이터셋의 디렉토리 구조: test, val, train으로 나눠져 있다. image에는 해당 이미지가 있고 label에는 해당 이미지에 해당하는 object 정보(클래스 이름, x, y, w, h값)가 저장되어 있다. 참고로 이미지파일명과 레이블파일명은 동일하다. (ex) ak12.jpg는 ak12.txt파일와 세트이다.)
from ultralytics import YOLO
# 모델 불러오기
model = YOLO(model='YOLO8n.pt', task='detect')
# 모델 학습시키기
model.train(data='/content/roboflowex2-1/data.yaml', # 학습할 데이터의 yaml파일 위치
epochs=150, # 학습할 횟수
patience=10, # early stop
pretrained=True, # 이미 학습된 가중치를 사용할 것인지
verbose=True,
seed=2023,
)
# 예측하기
results = model.predict(source='/content/test01.jpg',
save=True,
line_width=2)'Study > KT AIVLE School' 카테고리의 다른 글
| [KT AIVLE School] AI트랙 9주차 후기(언어지능 딥러닝) (0) | 2024.04.23 |
|---|---|
| [KT AIVLE School] AI트랙 5 & 6주차 후기(딥러닝) (2) | 2024.04.02 |
| [KT AIVLE School] AI 트랙 4주차 후기 (머신러닝) (0) | 2024.03.17 |
| [KT AIVLE School] AI트랙 3주차 후기 (미니프로젝트, 웹크롤링) (2) | 2024.03.10 |
| [KT AIVLE School] AI트랙 2주차 후기(데이터 처리, 데이터분석 및 의미찾기) (0) | 2024.03.06 |



