
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 에이블스쿨6기
- sklearn
- HUFS
- 딥러닝
- Python
- 내배카
- 내일배움카드
- numpy
- AIVLE
- jupyter notebook
- KT
- 미니프로젝트
- KT AIVLE SCHOOL
- keras
- 에이블데이
- pandas
- YOLO
- 자연어처리
- KT wiz
- KT에이블스쿨
- 해외연수
- Aivle school
- kaggle
- 에이블스쿨
- Anaconda
- AI
- AIVEL
- 코딩테스트
- 부트캠프
- 한국외대
- Today
- Total
Hyunn
[KT AIVLE School] AI트랙 9주차 후기(언어지능 딥러닝) 본문
9주차 일정
04.15 ~ 19 : 언어지능 딥러닝
저저번주 시각지능 딥러닝에 이어 언어지능 딥러닝(자연어처리) 수업이 시작되었다. 이번 수업은 고려대학교 김중헌교수님이 해주셔서 기대가 되었다.
TF-IDF
- TF(Term Frequency): 어떤 문장에서 빈도 수
- IDF(Inverse Documentary Frequency): 해당 문서(문장)에'만' 나오는 단어
→ 해당 문서에서만 많이 나오는 단어들이 대표성을 띤다. 예를들어, 'a', 'the', to'와 같은 단어는 문서의 대표성을 띄지 않는다. 따라서 학습할 때 위와같은 불용어에는 작은 가중치를 둔다.
$$TF-IDF = TF(t, d) \times IDF(t,D)$$
t: 내가 보고있는 단어 / d: 내가 보고있는 문서 / D: 문서들의 전체 집합
즉, 내가 보고 있는 문서에서 단어의 빈도 * 그 단어가 문서들의 전체 집합에서 나오는 횟수의 역수
예를들어, 어떤 두 문장이 있고 거기서 특정 기준으로 단어를 추출한다. 각 단어별로 TF-IDF값들을 구해서 벡터화 시키고 그 두 문장간의 특정 기준으로 유사도를 구할 수 있다. 여기서 '특정 기준'에 대해서는 후술하였다.
단어 표현
컴퓨터는 기본적으로 문자를 이해할 수 없으므로 단어를 벡터로 변환해야 한다.
One-Hot Encoding
: 단어를 벡터로 변환하는 가장 기본적인 방법이다. 하지만 자연어처리에서 쓰기에는 적절하지 않다. 그 이유로는,
- 모든 값이 0이고 단 1개의 값만 1값을 갖는다. 따라서 밀도가 매우 낮다. 현실에 있는 수 많은 단어를 원핫인코딩으로 표현하기에는 불가능하다.
- 새로운 단어나 사라지는 단어에 대응하기 어렵다. 벡터값이 변경될 때마다 새롭게 다시 학습해야 하므로 오버헤드가 크다.
- 단어들간 연관성을 표현할 수 없다.
- One-Hot Encoding 방식은 모든 값이 0이고 1개만 1이다. 예를들어, '사람'이라는 단어를 [0, 0, 1], '남자'라는 단어를 [0, 1, 0]으로 표현했을 때, 이 두 단어의 연관성을 표현할 수 없다. 서로 90도 관계를 갖는 벡터끼리는 연관성이 없기 때문이다. 하지만 '사람'과 '남자'는 어느부분 연관성이 있는 단어이다.
Word Embedding
: 단어들간의 관계를 나타내면서 단어를 숫자로 표현하는 법
| Words | Encoding | Embedding |
| King | [1, 0, 0, 0] | [1, 2] |
| Man | [0, 1, 0, 0] | [1, 3] |
| Queen | [0, 0, 1, 0] | [5, 1] |
| Woman | [0, 0, 0, 1] | [5, 2] |
위 표에서 King과 Man이 Embedding된 값을 살펴보면 2번째 값이 1만큼 차이나는 것을 확인할 수 있다. 이와 마찬가지로 Woman과 Queen도 2번째 값이 1만큼 차이난다. Man과 Woman을 살펴보면 1번째 값이 4만큼 차이난다. 따라서 King과 Queen은 1번째 값은 4만큼, 2번째 값은 1만큼 차이가 발생하는 것이다. 이처럼 Word Embedding으로 벡터화하면 단어들간 연관성을 표현할 수 있다.
Word2Vec
: Word Embedding을 하는 알고리즘 중 하나이다. 기본적인 아이디어로는 '어떤 단어 주변 단어는 그 단어와 연관되어있다' 이다.
단어들을 특정 window size만큼 순차적으로 확인하며 One-Hot Encoding을 진행한다. 예를들어, King Brave Man이 있고 window size가 1이라면 king 주변에는 Brave, Brave주변에는 King, Man이 있고, Man 주변에는 Brave가 있다. Word와 Neighbor를 One-Hot Encoding을 진행하고 word가 input, Neighbor가 output으로 설정해 학습을 진행한다.
| Word | Neighbor |
| King | Brave |
| Brave | King |
| Brave | Man |
| Man | Brave |
학습의 결과가 위 Embedding된 표처럼 되는 것이다.
유사도 판단
: 텍스트를 벡터화한 후 벡터화된 각 문장 간 얼마나 유사한지를 표현하는 방식(자카드 유사도, 코사인 유사도, 유클리디언 유사도, 멘헤튼 유사도 등)
자카드 유사도
: 두 문장을 각각 단어의 집합으로 만든 뒤, 두 집합을 통해 유사도 측정
- 측정법: A / B
- A: 두 집합의 교집합인 공통된 단어의 개수
- B: 집합이 가지는 단어의 개수
즉, [1, 2, 3]과 [1, 2, 4]의 자카드 유사도는 66.6%이다.
코사인 유사도
: 두 개의 벡터값에서 코사인 각도를 구하는 방법
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
sentence = ('오늘도 폭염이 이어졌는데요, 내일은 반가운 비 소식이 있습니다.',
'폭염을 피해 놀러왔다가 갑작스런 비로 망연자실하고 있습니다.')
vector = TfidfVectorizer(max_features=100) # 100개의 단어를 추출해서
tfidf_vector = vector.fit_transform(sentence) # 각 문장에 대한 벡터값을 구한다(TF-IDF사용).
print(cosine_similarity(tfidf_vector[0], tfidf_vector[0]))
# 같은 문장의 유사도를 측정했으므로 1값을 갖는다.
print(cosine_similarity(tfidf_vector[0], tfidf_vector[1]))
# 다른 문장의 유사도를 측정했으므로 0.07값을 갖는다.
유클리디언 유사도
: 두 벡터 간 거리로 유사도를 판단한다. 거리의 기준은 유클리디언 거리를 사용한다.
멘헤튼 유사도
: 두 벡터 간 거리로 유사도를 판단한다. 거리의 기준은 멘헤튼 거리를 사용한다.
거리를 측정하는 방법
민코프스키 거리(Minkowski Distance)
: 유클리드 거리와 멘해튼 거리를 일반화한 식
$$d(\overrightarrow{x}, \overrightarrow{y}) = (|x_1 - y_1|^p + |x_2 - y_2|^p + \dots + |x_n - y_n|^p)^{\frac{1}{p}}$$
p=1인 경우: 멘헤튼 거리 / p=2인 경우: 유클리디안 거리
Cosine Measure
$$ cos(\overrightarrow{x}, \overrightarrow{y}) = \frac{x_1y_1 + \dots + x_ny_n}{\sqrt{x_1^2 + \dots + x_n^2}\sqrt{y_1^2 + \dots + y_n^2}} $$
$$d(\overrightarrow{x}, \overrightarrow{y}) = 1-cos(\overrightarrow{x}, \overrightarrow{y})$$
첫 번째 식에서 분모는 벡터의 크기를 모두 없애고 방향만을 본다는 의미이다. 코사인 값은 -1 ~ 1을 가지므로 distance는 0 ~ 2값을 갖는다.
데이터를 표현하는 방법
- Data Matrix: 데이터 자체에 관심이 있음
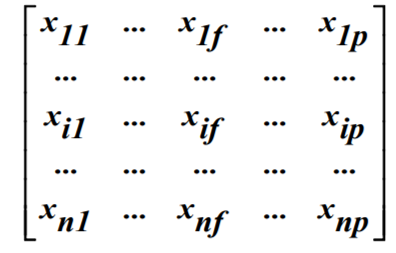
- Distance / dissimilarity matrix: 주어진 원소에 대해 거리가 얼마만큼 떨어져있는지를 나타냄
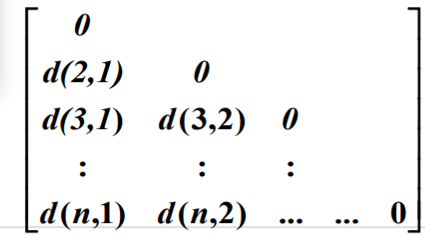

추천 시스템
Collaborative Filtering(CF): 사용자들의 행동이력을 분석
- 사용자의 행동이력을 분석해가며 비슷한 컨텐츠를 추천해준다.
- 단점: 아이템의 존재유무에 따라서 메트릭이 바뀐다.
- ex) 이 영화를 좋아했던 다른 사람들은 또 어떤 영화를 좋아해요?
- 즉, 사용자에 포커스를 맞추고 추천해준다.
Content-based Filtering(CBF): 아이템 자체를 분석
- 아이템의 벡터 값을 구해 비슷한 벡터값의 아이템을 추천해준다.
- ex) 라디오헤드를 좋아하는 사람은 콜드플레이도 좋아하지 않을까요?
- 즉, 아이템에 포커스를 맞추고 추천해준다.
현대 방식은 이 두 가지를 적절하게 비중을 두고 사용자에게 컨텐츠나 아이템을 추천한다.
Clustering vs. Classification
- 클러스터링
- 비지도학습으로 비슷한 것(관련있는 것)들끼리 묶는 문제
- 레이블을 제공하지 않는다.
- 일반적인 답은 있을 수 있지만 '정답'이란 것은 없다.
- 분류
- 지도학습으로, 새로운 데이터가 들어왔을 때, 그 데이터를 예측하는 것
K-means clustering
- K의 개수만큼 대표값을 정한다(랜덤).
- 대표값을 기준으로 clustering 한다. (대표값이 아닌 점들은 가까운 대표값과 같은 그룹으로 묶는다).
- 각 집단의 평균 점을 구하고 그 점과 가장 가까운 점을 대표값으로 변경한다.
- 새로정한 대표값 점이 기준이 되어서 다시 clustering을 진행한다.
- 클러스터링이 바뀌지 않을 때까지 이를 반복한다.
단점: K개수를 미리 정해주어야 한다.
Linear Regression
: 대표가 되는 선 하나를 찾는 문제
$$H(x) = Wx + b$$
W: 가중치
Cost Function(Loss Function)
$$\frac{1}{m}\Sigma^m_{i=1}{(H(x^i) - y^i)^2}$$
즉, 모델이 예측한 값과 실제값을 뺀 후 제곱한 값들의 평균을 구한 것이다. 이를 풀어서 쓰면 다음과 같다.
$$Cost(W, b) = \frac{1}{m}\Sigma^m_{i=1}{(Wx^i + b - y^i)^2}$$
따라서 Cost함수를 이차함수를 띤다.

위 이차함수에서 W로 편미분해서 그 값이 0인 곳이 최종 가중치로 결정된다. 이 때 learning rate는 기울기가 0인 값을 찾아가는 보폭인데 값이 너무 크다면 overshooting이 발생해 0인 지점을 찾지 못하게 될 것이고 너무 작다면 학습시간이 너무 오래걸릴 수 있으므로 '적절한' learning rate값을 주어야 한다(적절한이란 말이 참 애매하긴 하지만,,)
코드
torch
import torch
x_train = torch.FloatTensor([[1, 1], [2, 2], [3, 3]])
y_train = torch.FloatTensor([[10], [20], [30]])
W = torch.rand([2, 1], requires_grad=True)
b = torch.randn([1], requires_grad=True)
optimizer = torch.optim.SGD([W, b], lr=0.01)
# 1단계: 모델을 만든다.
def H(x):
return torch.matmul(x, W) + b # H(x) = Wx + b
# matmul은 행렬곲을 의미
# 2단계: 학습을 한다.
for step in range(2000):
cost = torch.mean((H(x_train) - y_train) ** 2) # cost = mean{(H(x) - y^2}
# 즉, 모델의 예측값 - 실제값의 제곱의 평균
optimizer.zero_grad() # 변화율 초기화
cost.backward() # 매개변수 조정
optimizer.step() # 계산된 gradient를 사용하여 모델의 매개변수 업데이트
# 3단계: 추론/테스트를 한다.
x_test = torch.FloatTensor([4, 4])
print(H(test).detach().item())
Keras
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
x_data = np.array([[1], [2], [3]])
y_data = np.array([[1], [2], [3]])
model = Sequential()
model.add(Dense(1, input_shape=(1, ))
model.compile(loss='mse', optimizer='adam')
model.fit(x_data ,y_data, epochs=1000, verbose=0)
model.summary()
print(model.predict(np.array([4])))
Keras가 훨씬 간편하고 쉬움에도 GitHub에 있는 많은 딥러닝 코드들이 torch로 된 것들이 많아서 torch도 알아두어야 한다!
Binary Classification
: 0인지 1인지 예측하는 문제
- Sigmoid 함수
$$sig(t) = \frac{1}{1+e^{-t}}$$
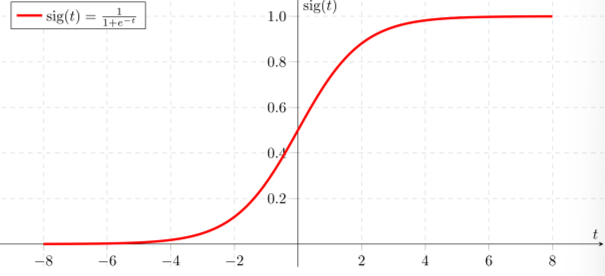
어떤 t값이 들어와도 0 ~ 1값을 갖는다. 따라서 t대신 Linear Regression식을 넣으면 다음과 같다.
- Model
$$g(X) = \frac{1}{1+e^{-W^TX}}$$
- Cost
$$Cost(W) = -\frac{1}{m}\Sigma \, y\,log(H(x)) + (1 - y)\, log(1-H(x))$$
이 때, 실제값이 0인데 H(x)가 0으로 예측했다면 log 1이 남는다. 따라서 cost는 0이 된다.
반대로 실제값이 1인데 H(x)가 0으로 예측했다면 log 0이 남게된다. 이는 -inf값을 가지는데 앞에 -가 있으므로 inf값을 가진다.
즉, 위 식에서 '+'를 기준으로 실제값이 0이면 앞 식이 0이 되고, 실제값이 1이면 뒷 식이 0이 된다.
Cost Function
원래 선형회귀분석에서는 직선의 방정식인 H(x)를 y(상수)와의 차이를 제곱하고 평균을 내주면 그 함수가 2차 함수이다. 따라서 최적화가 가능하다(즉, 그 코스트함수가 제일 작아지는 W값을 구할 수 있음).
그런데 이처럼 H(x)에 시그모이드를 적용하면 직선이 아니니, 거기에서는 y값을 빼고 제곱한다고 해서 2차함수가 나오지 않는다. 따라서 cost가 가장 작아지는 W를 찾는게 불가능하다. 그러므로 지수를 가지고 있는 시그모이드 특정상 로그함수를 쓰는 것이다!
코드
torch
import torch
x_train = torch.FloatTensor([[1, 1], [2, 2], [3, 3]])
y_train = torch.FloatTensor([[0], [0], [1]])
# 실제로는 x_train에는 단어나 문장의 벡터화된 값, y_train에는 0이나 1값이 들어간다.
W = torch.rand([2, 1], requires_grad=True)
# 가중치 값인 W는 x_train과 행렬 곱을 해야하므로 (1, 2)인 x_train과 shape를 맞춰 (2, 1)인 행렬이 되어야 한다.
b = torch.randn([1], requires_grad=True)
optimizer = torch.optim.SGD([W, b], lr=0.01)
# 1단계: 모델을 만든다.
def H(x):
return torch.sigmoid(torch.matmul(x, W) + b)
# 2단계: 학습을 한다.
for step in range(2000):
cost = -torch.mean(y_train * torch.log(H(x_train)) + (1 - y_train) * (torch.log(1 - H(x_train))
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 3단계: 추론/테스트를 한다.
x_test = torch.FloatTensor([4, 4])
print(H(x_test).detach().item())
Softmax
: 다중분류 문제에서 사용
이중분류기만을 사용해서 A, B, C를 한 번에 분류할 수는 없다. 따라서 3번의 분류가 필요하다.
(1) A인지 아닌지 (2) B인지 아닌지 (3) C인지 아닌지
입력이 (x1, x2)로 주어졌을 때
- A인지 아닌지 판별
$$x_1 \cdot W_{A1} + x_2 \cdot W_{A2}$$ - B인지 아닌지 판별
$$x_1 \cdot W_{B1} + x_2 \cdot W_{B2}$$ - C인지 아닌지 판별
$$x_1 \cdot W_{C1} + x_2 \cdot W_{C2}$$
위 3개 식을 한 번에 쓰면 다음과 같다.

위 식을 지나면 각각 (0.87, 0.2, 0.2)와 같은 결과를 얻게 될 것이다(수치는 예시). 이를 argmax값을 구하면 된다. 참고로 코드로 softmax를 구하게 되면 모든 수의 합이 1이 되는데, 이는 keras나 torch에서 보정해준 것이다. 즉, 절대평가에서 상대평가로 바꾼 것이라고 생각하면 된다.
Cost Function: Cross Entropy
$$C(S, L) = -\Sigma \, {L_i \, log(S_i)}$$
L: 예측 값 / S: 실제 값
| L | S | Cost |
| [1, 0, 0] | [1, 0, 0] | -1 log 1 - 0 log 0 - 0 log 0 = 0 |
| [0, 1, 0] | -1 log 0 - 0 log 1 - 0 log 0 = inf | |
| [0, 0, 1] | -1 log 0 - 0 log 0 - 0 log 1 = inf |
따라서, softmax에서 y값은 항상 One-Hot Encoding이 되어있어야 한다.
신경망
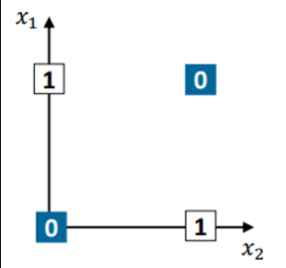
위 그림에서 0과 1을 1개의 선으로 나눌 수 있을까? 위 그림은 x와 y를 XOR한 값이다. 즉 아래 표와 같다.
| X1 | X2 | X1 XOR X2 |
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
결론적으로는, 위 그림을 단 1개의 선으로 0과 1을 나누지 못한다! 그렇다면 아래와 같은 신경망을 거친다고 생각해보자.
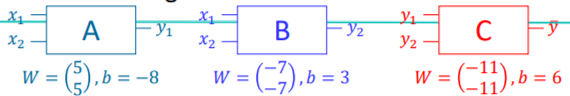
예를들어, x1 = 0 이고, x2 = 1 일 때, A라는 신경망을 거치고 나면 y1 = -3이 출력된다((0 * 5 + 1 * 5) + (-8)). 이후 B라는 신경망을 거치면 y2는 -11이 출력된다. 하지만 이진분류기이므로 sigmoid함수를 거쳐 y1, y2값 모두 0이 된다. 0값으로 바뀐 y1과 y2를 C라는 신경망의 입력으로 들어가면 y값은 6이 된다. C또한 sigmoid함수를 거치므로 1값을 가지게 된다. 실제로 0 XOR 1은 1값을 가진다. 이와 같이 0, 0부터 1, 1까지 입력을 정리하면 다음 표와 같다.
| X1 | X2 | y1 | y2 | y(예측값) | XOR(실제값) |
| 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 1 | 1 |
| 1 | 1 | 1 | 0 | 0 | 0 |

위 그림에서 모든 노드는 연결되어 있다고 가정하자. input 벡터의 크기는 (1, 3)이다. 그리고 hidden layer1의 node가 4개이므로 (3, 4)가 된다. 그럼 hidden layer2의 입력이 4개 이므로 (4, 4)가 된다. 즉 (n, m)에서 n은 이전 layer의 출력크기가 결정 한다. 마지막으로 output layer에서는 (4, 1)크기의 행렬이 된다. 따라서 위 신경망에서 제일 뒤에 코스트 함수가 있고, 경사하강법으로 한 번의 점프르 뛸 때, 41개(가중치: 32개, 편향: 9개) 파라미터가 업데이트 된다.
코드(torch)
import torch
x_train = torch.FloatTensor([[0, 0], [0, 1], [1, 0], [1, 1]])
y_train = torch.FloatTensor([[0], [1], [1], [0]])
W_h = torch.randn([2, 3], requires_grad=True) # 입력의 크기가 2이므로 0번째가 2가 됨
## 노드의 개수를 3개로 설정했으므로 1번째가 3이 됨
b_h = torch.randn([3], requires_grad=True) # 노드의 개수가 3개로 설정했으므로 bias도 3이 됨
W_o = torch.randn([3, 1], requires_grad=True) # 이전 layer 노드의 개수가 3개이므로 0번째가 3이 됨
b_o = torch.randn([1], requires_grad=True)
optimizer = torch.optim.SGD([W_h, b_h, W_o, b_o], lr=0.01)
# 딥러닝 1단계: 모델을 만든다.
def H(x):
HL1 = torch.sigmoid(torch.matmul(x, W_h) + b_h)
return torch.sigmoid(torch.matmul(HL1, W_o) + b_0)
# 딥러닝 2단계: 학습을 한다.
for step in range(50000):
cost = -torch.mean(y_train * torch.log(H(x_train)) + (1 - y_train) * torch.log(1 - H(x_train))
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 딥러닝 3단계: 추론/테스트를 한다.
print(H(x_train))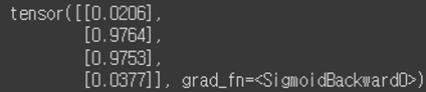
PCA / LDA
- 차원의 저주: 공간의 차원이 증가함에 따라 데이터의 밀도가 급격히 감소하고, 이로인해 데이터 분석이나 머신러닝 모델의 성능에 부정적인 영향을 미치는 현상
- 차원을 줄이는 방법
- 차원의 축소(Feature Extraction)
- 차원의 선택(Feature Selection)
- PCA: 차원이 축소되더라도 모양을 최대한 유지
- ex) 내 3차원 모습을 그림자로 나타내는데 해가 45도 방향으로 비친 2차원 그림자는 내 모습을 최대한 반영하면서 2차원으로 차원축소가 일어났다.
- LDA: 분류하기 쉬운 방향으로 차원을 축소(클러스터링)
- ex) 내 3차원 모습을 그림자로 나타내는데 해가 90도 방향으로 비친 2차원 그림자는 개체간 분류를 시켜줌.
GAN
따로 공부를 좀 더하고 올리겠습니다,,,
'Study > KT AIVLE School' 카테고리의 다른 글
| [KT AIVLE School] AI트랙 7주차 후기(시각지능 딥러닝) (0) | 2024.04.10 |
|---|---|
| [KT AIVLE School] AI트랙 5 & 6주차 후기(딥러닝) (2) | 2024.04.02 |
| [KT AIVLE School] AI 트랙 4주차 후기 (머신러닝) (0) | 2024.03.17 |
| [KT AIVLE School] AI트랙 3주차 후기 (미니프로젝트, 웹크롤링) (2) | 2024.03.10 |
| [KT AIVLE School] AI트랙 2주차 후기(데이터 처리, 데이터분석 및 의미찾기) (0) | 2024.03.06 |



