
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- KT wiz
- kdt
- pandas
- sklearn
- 에이블스쿨6기
- YOLO
- AIVEL
- AIVLE
- KT에이블스쿨
- numpy
- 한국외대
- KT
- Aivle school
- 내일배움카드
- 코딩테스트
- kaggle
- KT AIVLE SCHOOL
- 해외연수
- Python
- 빅프로젝트
- jupyter notebook
- 에이블스쿨
- AI
- Anaconda
- HUFS
- 부트캠프
- 딥러닝
- 에이블데이
- keras
- 내배카
- Today
- Total
Hyunn
[KT AIVLE School] 3차 미니프로젝트 후기 본문
일정
03/27 ~ 28: 스마트폰 센서 기반 모션 분류
03/29: Kaggle Competition
이번 미니프로젝트는 팀전과 개인전으로 나뉘었습니다. 두 번 모두 '스마트폰 센서 기반 모션 분류'라는 주제지만 다른 데이터 셋이 주어졌습니다.
스마트폰 센서 기반 모션 분류
중요도 분석
먼저 중요도 기반으로 feature들을 분석했습니다. RandomForest를 사용해 변수 중요도를 측정해봤습니다.

tGravityAcc-min()이라는 변수가 Activity를 결정하는데에 가장 큰 중요도를 가졌는데, 저 센서가 어떤 역할을 하는지는 잘 모르겠지만 중요한 변수임은 알 수 있었습니다.
is_dynamic변수 추가
6개의 target값을 dynamic과 static으로 분리해봤습니다. Standing, Walking, Waling_Downstairs, Waling_Upstairs는 1로, 나머지는 0으로 설정하고 target을 is_dynamic으로 변경했습니다.
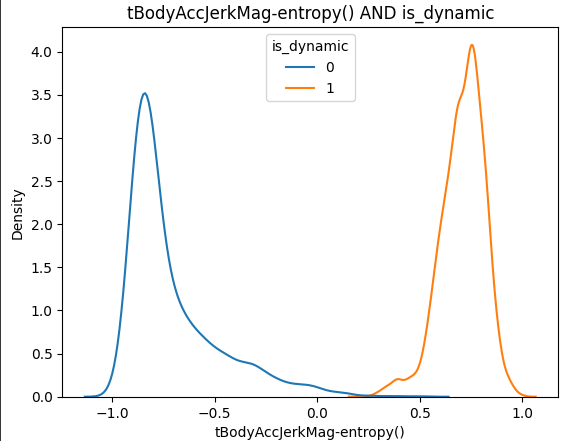
그랬더니 is_dynamic을 결정하는데 가장 중요도가 높은 변수는 tBodyAccJerkMag_entropy()였습니다. 무슨 센서인지는... 어려워서 모르겠어요...
활동별로 중요도 분석하기
6개의 활동별로 센서의 중요도 또한 분석해봤습니다.
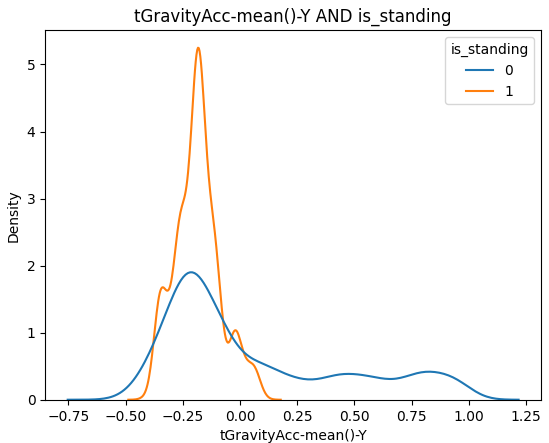
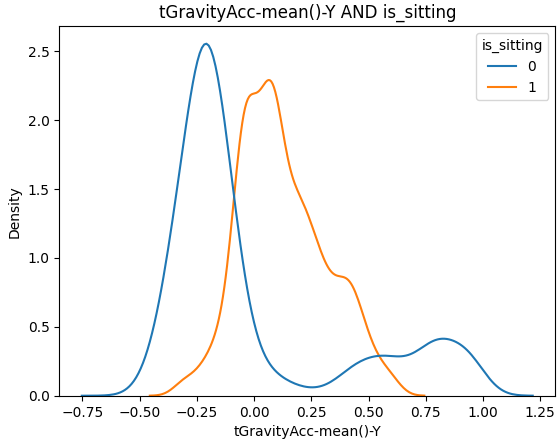
모든 그래프를 첨부하지는 못했지만 6개의 target별로 모두 중요도를 구해봤습니다.
이후, 모든 센서별 중요도를 merge했습니다.
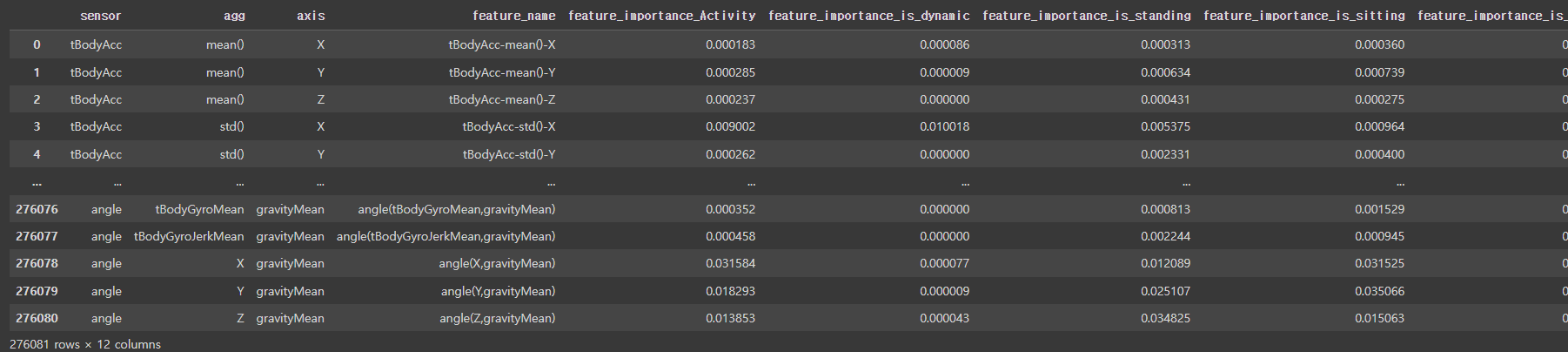
이 DataFrame은 추후 '단계별 모델링'에서 사용할 예정이에요.
기본 모델링
처음에 제공해주신 센서 데이터로 모델링을 진행해봤습니다.
학습을 위한 기본적인 전처리과정(데이터 분할, 스케일링 등)을 마치고 모델을 학습했습니다.
- KNN
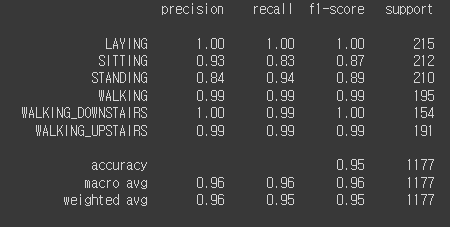
KNN으로 학습한 결과 - XGB
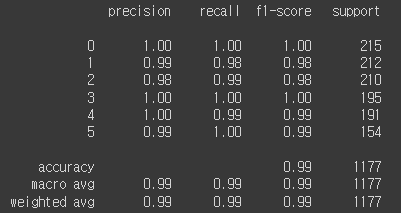
XGB로 학습한 결과 - LGBM
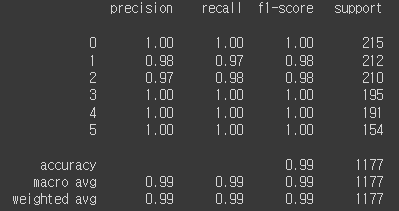
세 모델 모두 공통적으로 학습이 매우 잘되었습니다. KNN을 제외하고는 99%의 정확도를 보였습니다. 기본적인 데이터 정제를 하지 않았는데도 학습이 매우 잘 되어 당황했습니다. 그래서 팀별 모임 때 팀원분들과 토의도 하고 튜터님이 방문하셨을 때 여쭤보니 이 데이터는 원래 깨끗한 데이터라 학습이 잘되는게 정상이라고 하셨습니다. 다양한 모델을 사용하도록 하는 것이 목적이었다고 하시더라구요. 그리고 feature의 개수를 줄여도 정확도가 높게 나와 모델의 복잡도를 줄여보는게 어떠겠냐는 권유도 받았습니다.
단계별 모델링
저번 단계에서는 기본적인 데이터로만 모델링을 했다면 단계별 모델링에서는 이전에 만든 is_dynamic, is_standing 등과 같은 중요도를 기반으로 정적(static)인지 동적(dynamic)인지를 판별 후, Activity상태를 판별하는 모델을 만들어 봤습니다. 즉, 두 단계에 걸쳐 예측하는 방식입니다.
def func(data):
drop_col = 'subject'
target = 'Activity'
# subject열 삭제하기
data.drop(drop_col, axis=1, inplace=True)
# 데이터 나누기
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 동적, 정적 예측하기
is_dynamic = model_dl.predict(x)
is_dynamic = np.where(is_dynamic > 0.5, 1, 0)
x['Activity_dynamic'] = pd.DataFrame(is_dynamic)
# 동적, 정적 데이터프레임 나누기
static = x.loc[x['Activity_dynamic'] == 0]
dynamic = x.loc[x['Activity_dynamic'] == 1]
# 동적, 정적 따로 예측하기
pred_static = model_rf2.predict(static)
pred_dynamic = model_rf3.predict(dynamic)
# 예측 결과 합치기
static['pred'] = pred_static
dynamic['pred'] = pred_dynamic
data = pd.merge(data, dynamic, how='left')
data = pd.merge(data, static, how='left')
display(data)
다음과 같이 함수로 만들어 예측해본 결과 이 또한 99%의 정확도를 보여주었습니다.
다행이(?)도 깨끗한 데이터를 제공받아서 정확도가 높게 나왔지만 내일있을 Kaggle은 아무런 전처리 없이 학습시키면 65%..?정도의 정확도를 보여준다고 강사님께서 겁을 주셨습니다... 내일을 위해 이틀동안 연습을 해 코드에 좀 더 익숙해질 수 있어서 의미 있는 시간이었던 것 같습니다.
Kaggle Competition
Kaggle?
캐글은 예측모델 및 분석 대회 플랫폼입니다. 기업 및 단체에서 데이터와 해결과제를 등록하면 데이터 과학자들이 이를 해결하는 모델을 개발하고 경쟁하는 플랫폼이라고 합니다.
이번 target은 걷기, 뛰기, 천천히 걷기, 계단 오르기, 계단 내려가기, 서있기, 앉아있기, 누워있기, 자전거타기, 서서 자전거 타기, 자전거에 앉아있기 이렇게 11가지 라벨이 존재했습니다.

처음 데이터를 받았을 때 날짜가 있어서 바로 drop을 이용해서 삭제했습니다. 이후 결측치 처리를 했습니다. 저는 결측치를 레이블별 센서 평균값으로 채워 넣었습니다.
결측치 처리 후, 바로 학습을 진행했습니다.
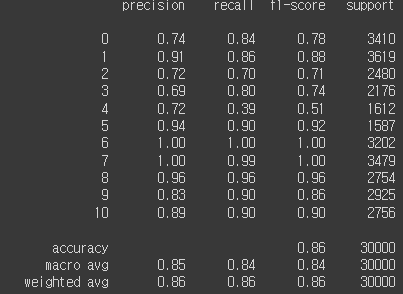
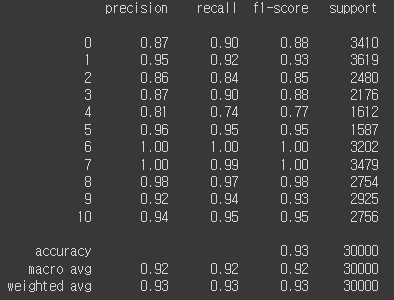
생각보다 잘 나와서 그대로 제출했습니다. 그랬더니 89%의 정확도가 나왔고 20등대를 기록해서 '이정도면 됐다' 싶었습니다. 하지만 시간이 갈수록 순위가 점점 떨어져 100등 밑으로 추락했습니다..ㅠㅠ
마감 30분 전에 깨달았는데, 처음에 시계열 데이터를 삭제한게 실수인 것 같은 생각이 들었습니다. 시계열 데이터가 밀리초(ms)까지 기록되어 있었는데 결측치도 선형보간법으로 채울 수 있을 것 같았고, 보통 한 가지 동작을 꾸준히 이어가지 앉아있다가 1초 후에 걷고 1초 후에 자전거를 타고 1초 후에 다시 누워있는 등 이러한 양상은 보이지 않는다는 생각이 떠올랐습니다. 그래서 급하게 다시 데이터를 전처리 하는 과정에서 마감시간이 다 되어 제출하지는 못했습니다.
전체 발표 시간에 다른 분들이 어떻게 했는지 들어봤는데 역시나 시계열데이터를 활용했었습니다. 아이디어는 떠올랐지만 시간 내에 구현하지 못해 정말 아쉬었고 다음번에는 현재 순위가 높다고 자만하지말고 더 성능을 높힐 수 있는 방법이 없는지 생각해 볼 것 같습니다...!!!
Epilogue

5반 반장님 장기자랑 시간...


5반 반장님의 맥주 따르기 실력....
교육장 오시면 팀원과 재밌게 프로젝트 할 수 있습니다 ^_^
'Study > KT AIVLE School 기자단' 카테고리의 다른 글
| [KT AIVLE School] 5차 미니프로젝트 후기(AICE 대비) (0) | 2024.04.30 |
|---|---|
| [KT AIVLE School] 코딩마스터즈 및 코딩테스트(feat. 스터디) (0) | 2024.04.23 |
| [KT AIVLE School] 1차 미니프로젝트 후기 (0) | 2024.03.23 |
| [KT AIVLE School] KT Wiz 홈 개막전 X AIVLE School (1) | 2024.03.23 |
| [KT AIVLE School] 오프닝 데이 (2) | 2024.03.18 |


